

Le 4 Octobre 2021, une panne mondiale inédite a touché le géant américain Facebook : tous les services Facebook, Instagram, WhatsApp et Messenger étaient inaccessibles pendant plus de 7 heures affectant 3,5 milliards de personnes soit près de la moitié de la planète et des 200 millions de PME qui utilisent l’un de ses services.
Dans cet article nous allons nous intéresser à cet incident pour essayer d’expliquer ce qui s’est produit, le but recherché n’est pas d’identifier un coupable mais plutôt essayer de comprendre et tirer les bons enseignements à retenir pour apporter plus de résilience et de disponibilité à nos infrastructures réseaux : Si Facebook avec son infrastructure réseau très sophistiqué et son armada d’ingénieurs très reconnus et expérimentés ont subi une panne aussi longue et importante, c’est que cela peut arriver à tout le monde et peut durer aussi longtemps.
Comme je ne travaille pas chez Facebook et que je ne connais pas en détail leur architecture, je ferai certaines hypothèses (qui n’engagent que moi) par rapport aux différents communiqués publiés par des acteurs fiables du marché.
Pourquoi les services Facebook n’étaient plus joignables ?
Pour atteindre n’importe quel site sur internet, on doit d’abord résoudre son nom en adresse IP, en effet, dans l’usage des services l’utilisateur retient plus facilement une URL comme www.facebook.com qu’une adresse IP (exemple 179.60.192.36).
Pour permettre cette résolution, on va interroger des annuaires (DNS) qui vont permettre par la suite d’indiquer le chemin à suivre à la passerelle (routeur) pour atteindre une destination.
Dans le cas de Facebook, ils disposent de quatre serveurs DNS (A,B,C et D) :
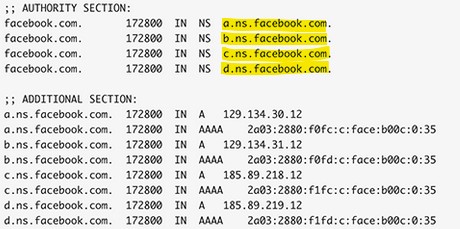
Vers 15 :40 (UTC), tous les annuaires DNS de Facebook n’étaient plus joignables rendant indisponible l’accès à ses services, les serveurs DNS « Root Internet» ne pouvaient plus joindre les DNS « Facebook » :
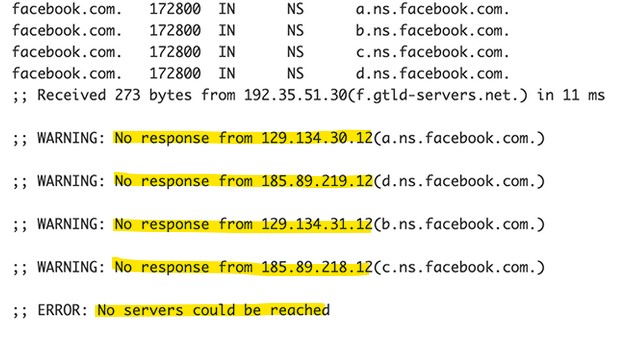
Résultats : les applications s’appuient fortement sur la résolution de nom DNS pour pouvoir fonctionner correctement et les serveurs DNS de Facebook n’étaient plus accessibles.
Pourquoi les serveurs DNS de Facebook sont devenus tous injoignables ?
On peut penser qu’il y a eu un mauvais geste d’exploitation impactant toute l’infrastructure DNS, dans ce cas, il n’y aura pas eu une coupure totale et mondiale pendant 7h puisque certains clients vont toujours pouvoir fonctionner en s’appuyant sur des caches existants et aussi la remise (ou autre moyen de réparation) en service du DNS est généralement plus rapide.
On peut aussi penser qu’il s’agit d’une attaque Cyber Sécurité avec comme conséquence un déni de service, mais pour ce type d’attaque, on observe souvent un ralentissement important des services sans les couper totalement, de plus ces attaques sont aujourd’hui bien supervisées par différents acteurs spécialisés , les alertes avec les actions associés sont souvent bien assimilées par les équipes d’exploitation. (surtout les GAFA)
La vraie réponse à cette question se trouve ailleurs : les serveurs DNS sont devenus injoignables à cause d’un mauvais apprentissage coté réseau (eh oui, c’est encore la faute du réseau ).
Facebook héberge son infrastructure DNS dans ses propres DataCenters, vers 15:39 les réseaux IPv4/IPv6 associés (ex : 129.134.30-31.0/24 et 185.89.218-219.0/24) ont disparu totalement de la table de routage d’ Internet : les routeurs Internet de Facebook ont annoncé une mise à jour massive de leur table de routage (BGP Withdraw) faisant disparaitre une centaine de préfixes de leur réseau, parmi ces réseaux figurent évidement les réseaux d’infrastructures qui hébergent les services DNS.
Cette mise à jour de la table de routage BGP a coupé entièrement Facebook du reste du monde, plus aucune passerelle sur internet ne savait le chemin pour joindre le réseau Facebook.
Enseignements :
Le DNS est un service très critique, il est préférable d’héberger le DNS (ou au moins quelques serveurs) chez d’autres fournisseurs et s’assurer que ces derniers utilisent des opérateurs différents (pour couvrir la panne opérateur), c’est le choix qu’a fait Amazon par exemple pour son infrastructure DNS.

Pourquoi cette mise à jour de la table de routage BGP a supprimé tous les réseaux Facebook d’internet?
Facebook n’a pas communiqué sur la raison technique de ce changement, on sait juste à travers un communiqué officiel qu’il y a eu un changement de configuration sur le backbone qui relie l’ensemble de leur DC, ce changement a interrompu par la suite toutes les communications avec Internet.
BGP est un protocole de routage robuste et puissant qui a déjà fait ses preuves sur plusieurs années, il est utilisé par tous les opérateurs pour acheminer le Trafic sur Internet, il n’est pas rare de constater des mises à jour sur ce protocole pour optimiser le routage et améliorer le ressentit utilisateur, ces mises à jour sont aussi réalisées pour permettre des opérations de maintenance sur les infrastructures réseaux par le changement du chemin de routage.
Pour Facebook, je ne pense pas qu’un humain s’est connecté sur tous les routeurs pour exécuter la même action destructrice, ces modifications de configurations sont généralement automatisés et s’exécutent à travers une interface (web ou autres) qui pousse une même configuration sur un ensemble d’équipements.
Peut-être que la modification de configuration était destinée à la base à quelques équipements pour des opérations de maintenance et s’est retrouvée généralisée à l’ensemble de l’infrastructure (bug ou inattention de l’exploitant).
Enseignements :
Il faut sécuriser dans les outils d’administration/automatisation les gestes de configurations critiques qui peuvent s’exécuter sur un nombre important d’équipements et engendrer une destruction massive du réseau, exemple interdire par défaut la suppression de certains préfixes critiques (DNS, VPN, WWW, ..) dans BGP, interdire par défaut certaines configurations critiques qu’on estime préférable qu’elle soit exécutée à l’ancienne par l’humain, peut être même aller plus loin et interdire toute action de modification de configuration exécutée sur un ensemble d’équipement qui partage la même criticité (exemple cœur de réseau DC, routeurs Internet, ..), il faut imposer dans ce cas de créer deux (ou plusieurs) groupes d’équipements et exécuter les actions de configuration séquentiellement sur chaque groupe, cela prendra un peu plus de temps dans la réalisation mais permettra d’introduire la modification de configuration d’une façon plus sécurisée.
Pourquoi il n’était pas possible de remettre rapidement les routes supprimés sur Internet et diminuer le temps de panne qui a duré plus de 7h ?
Par expérience et pour avoir assister et dépanner certains réseaux critiques, quand une panne réseau dure assez longtemps c’est qu’il y un problème important avec la technologie ou l’outil qui contrôle la solution réseau (plan de control ou contrôleur).
Quand l’outil (exemple contrôleur) qui permet de se connecter, vérifier et reconfigurer la solution n’est plus disponible pour pouvoir réparer, c’est que l’impact sera très fort, beaucoup de temps sera consommé pour juste pouvoir se connecter sur les équipements.
Imaginons que votre outil de configuration (serveur de rebond, bastion, contrôleur, automate) est le seul habilité à pousser une configuration sur le réseau, si cet outil n’est plus disponible à cause de la panne réseau (exemple ces outils sont sur une infra de virtualisation qui elle-même est impactée par le problème réseau), vous ne pouvez plus vous connecter pour réparer, je pense que Facebook se sont retrouvé dans cette situation, il avait un réseau « sans tête » pour le reconfigurer et le réparer.
Il y avait certes toutes les compétences réseau nécessaires par contre ils ne pouvaient pas se connecter sur les outils pour faire un premier diagnostic et réparer ensuite. C’est ce qui arrivé il y a quelques temps à Google, ils avaient réalisé une opération de maintenance qui a impacté la région du réseau qui hébergeait leur contrôleurs réseaux, par conséquent, ils ne pouvaient plus se connecter sur ces contrôleur et réparer rapidement : l’incident de Google a duré presque quatre heures.
Enseignements :
Il faut être en mesure de se connecter à tout moment sur l’infrastructure d’administration indépendamment de l’état fonctionnel du réseau de production, ces accès ne doivent pas être fait en inband, il faut plutôt privilégier une autre infrastructure réseau séparée (out of band) qui porte les équipements critiques du réseau et tout l’outillage nécessaire pour exploiter dans de bonnes conditions le réseau.
Souvent, on installe une infrastructure physique séparée pour connecter les interfaces de management des équipements mais on oublie de laisser certaines briques indispensables et essentielles (comme serveurs d’authen (LDAP), DNS, serveurs de rebond, équipements opérateur, ..) dans l’infrastructure de production. Si cette dernière présente un soucis, il sera compliqué (à cause de ses dépendances) de se connecter sur l’infrastructure OOB pour faire du troubleshooting.
Il faut pour cela analyser et restreindre toutes les dépendances avec la production pour réaliser les gestes d’exploitation au quotidien, idéalement faire des exercices et s’assurer que si le pire devait arriver les équipes sont prêtes pour intervenir : plus on réduit le temps d’accès aux équipements, plus on réduit le temps d’indisponibilité des services.
Cela présente un coût, mais dans la transformation digitale qu’on vit, il devient capital de fiabiliser le réseau, disposer en interne des bonnes ressources techniques et enfin avoir les procédures d’intervention rapide en cas de sinistre important.
Conclusion :
Dans notre monde numérique, le réseau fait partie essentielle et intégrante du patrimoine des entreprises, il faut le protéger et le fiabiliser dans les années à venir.
Cela passe par une valorisation du métier d’ingénieur ou expert réseau, par une reconnaissance dans l’organisation des entreprises, une internalisation de certaines parties très critiques du réseaux (exemple cœurs de réseau) et aussi avoir du bon sens dans les procédures d’exploitation et d’automatisation, comme toujours, il ne faut pas tomber dans l’excès car le retour de bâton peut faire très mal.
[UPDATE 06/10/2021 22h 45min :]
Facebook ont publié un update plus détaillé sur la source du problème, comme analysé plus haut dans l’article, un automate a lancé une commande dangereuse qui a « bypassé » les outils de vérification de la conformité des commandes (à cause d’un bug) et a entrainé une coupure totale des accès et des outils d’administration, ils ont aussi perdu beaucoup de temps pour se connecter sur les équipements à cause d’une procédure de sécurité ultra renforcée implémentée sur les équipements, il ne suffisait pas d’être physiquement devant l’équipement mais il fallait aussi dérouler certaines procédures spécifiques, la chronologie des événements semble être la suivante (d’après le communiqué de Facebook) :
1) Opération de maintenance réseau pour vérifier la capacité du réseau avec un outil
2) L’outil a déclenché une mauvaise configuration sur les équipements (probablement lié à une erreur humaine)
3) Le système de vérification des commandes « dangereuses » n’a pas pu identifier et arrêter son exécution à cause d’un bug identifié.
4) Déconnexion de tous les DC de Facebook de leur Backbone, ce dernier leur permet d’aller sur Internet
5) Un automate configuré sur les serveurs DNS permet d’arrêter automatiquement les annonces en BGP des préfixes en cas de détection d’une déconnexion du Backbone.
6) Perte de tous les moyens d’accès distants pour pouvoir réparer y compris l’accès au réseau Out Of Band.
7) Déplacement physique sur site mais les procédures de connexion en local sur les équipements sont durcis (pour des raisons de sécurité) et compliquent la taches aux experts réseaux.
8) Redémarrage dans la douleur des services à cause de la forte charge de trafic.
Je pense que Facebook a tellement automatisé et tellement sécurisé les infrastructures sans jamais se dire que cela peut se retourner contre eux. Ils ont passé largement plus de temps à rétablir les accès sur les équipements, la correction technique a ensuite été rapide, c’est le point clé à retenir : éviter de tomber dans l’excès et faire les choses au plus simple ..
Source : https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
A méditer …