

BGP (Border Gateway Protocol) est aujourd’hui incontournable !! C’est le protocole de routage qui gouverne le plus grand réseau du monde : le réseau Internet.
Les usages du BGP sont multiples et variés, en effet, ce protocole est aujourd’hui présent dans tous les environnements (LAN DC, LAN Entreprise, Service Provider, Sécurité) pour fournir des services avancés avec une politique de routage plus appropriée : BGP a encore devant lui de très belles années à venir !
Dans cet article, nous allons détailler la fonctionnalité « BGP Link Bandwidth », elle permet d’implémenter des mécanismes de partage de charge (bgp multipath) sur des liens ne disposant pas de la même bande passante : Il s’agit donc de répartir le trafic proportionnellement par rapport à la bande passante des liens.
Pour mieux illustrer le fonctionnement ainsi que l’intérêt de cette fonctionnalité, étudions le cas d’une entreprise connectée sur Internet à travers un opérateur ISP1 qui propose les débits 100 Mbits (Fès) et 50 Mbits (Marrakech) :
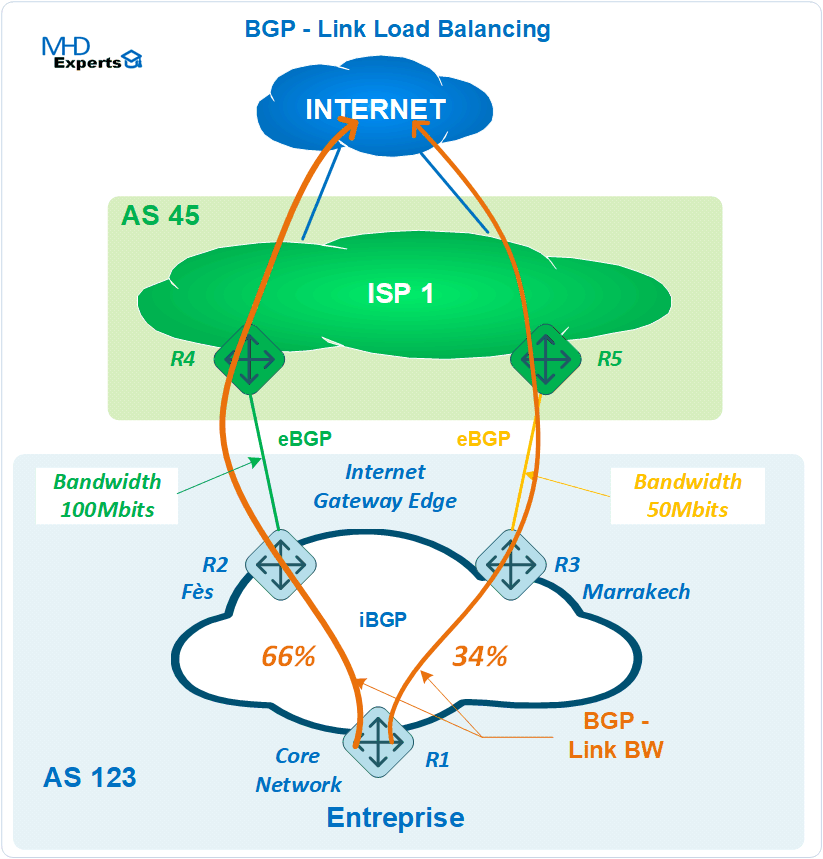
Architecture :
Les caractéristiques de cette architecture sont résumées dans les lignes qui suivent :
- L’Entreprise (AS 123) est représentée par les trois routeurs (R1, R2 et R3), ces derniers forment des relations d’adjacences en iBGP.
- L’ISP 1 (AS 45) est représenté par les routeurs R4 et R5.
- L’ISP1 fournit un accès Internet à 100 Mbits à l’Entreprise avec un raccordement eBGP (entre R2 et R4).
- L’ISP1 fournit un accès Internet à 50 Mbits à l’Entreprise avec un raccordement eBGP (entre R3 et R5).
Objectif recherché :
L’objectif recherché est de permettre à l’Entreprise d’utiliser ses sorties Internet en partage de charge qui tient compte des débits fournis par l’opérateur ISP1 (100 Mbits et 50 Mbits).
Il s’agit donc d’implémenter UCMP ( Unequal Cost MultiPath) sur le protocole BGP pour permettre à l’AS 123 de répartir le trafic en 66% vers le lien 100 Mbits et 34% vers le lien 50 Mbits.
Cette fonctionnalité va permettre aussi à l’Entreprise d’utiliser d’une façon plus optimale ses sorties Internet, dans souvent des cas, il n’est pas possible de provisionner un même débit pour des liaisons opérateurs, soit pour des raisons de coûts, techniques ou autres ..
Configurations initiales :
Les configurations initiales BGP sont assez simples, elles sont résumés dans les lignes qui suivent :
R1 :
router bgp 123
bgp log-neighbor-changes
neighbor 2.2.2.2 remote-as 123
neighbor 2.2.2.2 update-source Loopback0
neighbor 3.3.3.3 remote-as 123
neighbor 3.3.3.3 update-source Loopback0
R2 :
router bgp 123
bgp log-neighbor-changes
neighbor 1.1.1.1 remote-as 123
neighbor 1.1.1.1 update-source Loopback0
neighbor 1.1.1.1 next-hop-self
neighbor 3.3.3.3 remote-as 123
neighbor 3.3.3.3 update-source Loopback0
neighbor 3.3.3.3 next-hop-self
neighbor 10.10.24.4 remote-as 45
R3 :
router bgp 123
bgp log-neighbor-changes
neighbor 1.1.1.1 remote-as 123
neighbor 1.1.1.1 update-source Loopback0
neighbor 1.1.1.1 next-hop-self
neighbor 2.2.2.2 remote-as 123
neighbor 2.2.2.2 update-source Loopback0
neighbor 2.2.2.2 next-hop-self
neighbor 10.10.35.5 remote-as 45
R4 :
router bgp 45
bgp log-neighbor-changes
network 4.4.4.4 mask 255.255.255.255
neighbor 10.10.24.2 remote-as 123
R5 :
router bgp 45
bgp log-neighbor-changes
network 5.5.5.5 mask 255.255.255.255
neighbor 10.10.35.3 remote-as 123
Design de la solution :
Le principe de fonctionnement de la solution consiste à transmettre au sein de l’AS 123 une information qui indique la bande passante des sorties Internet (50 Mbits et 100 Mbits) afin qu’elle soit prise en compte dans les mécanismes de partage de charge du protocole BGP, pour ce faire :
- Les routeurs de sortie Internet (R2 et R3) ont connaissance de la bande passante vers l’ISP1, ils encodent cette information dans une communauté BGP et la transmettent ensuite au sein de l’AS 123 en iBGP vers tous les voisins.
- La communauté utilisée pour représenter la bande passante des liens utilise un format en 4 Octets, elle est prise en compte dans les mécanismes de partage de charge (bgp multipath), cependant, pour que deux chemins soient désignés comme égaux pour le partage de charge, BGP impose que les paramètres (weight, localpref, origin, as-path length, MED et IGP cost to nexthop) soient identiques.
- Cette fonctionnalité porte la nomenclature « DMZ Link Bandwidth » chez Cisco, Juniper la propose aussi.
- Les fonctionnalités « maximum-paths ibgp » et « bgp dmzlink-bw » permettent d’activer les mécanismes de partage de charge en tenant compte de la bande passante des liens.
Configuration de la solution :
R1 :
router bgp 123
bgp dmzlink-bw
neighbor 2.2.2.2 send-community both
neighbor 3.3.3.3 send-community both
maximum-paths ibgp 2
R2 :
router bgp 123
bgp dmzlink-bw
neighbor 1.1.1.1 send-community both
neighbor 3.3.3.3 send-community both
neighbor 10.10.24.4 dmzlink-bw
R3 :
router bgp 123
bgp dmzlink-bw
neighbor 1.1.1.1 send-community both
neighbor 2.2.2.2 send-community both
neighbor 10.10.35.5 dmzlink-bw
Pour les tests, nous allons simuler internet en déclarant la même interface loopback45 (45.45.45.45/32) sur les deux routeurs R4 et R5 puis l’annoncer en BGP vers l’Entreprise :
R4 & R5 :
interface Loopback45
ip address 45.45.45.45 255.255.255.255
!
router bgp 45
network 45.45.45.45 mask 255.255.255.255
Vérifications :
Vérifications du routage BGP et du bon fonctionnement du BGP MultiPath :
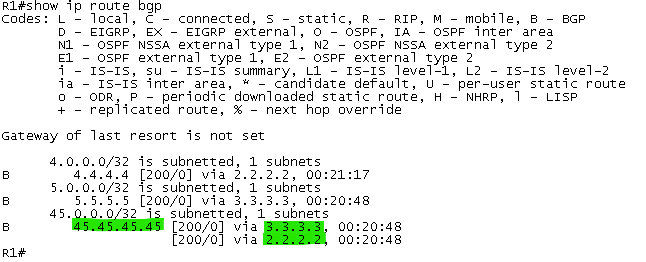
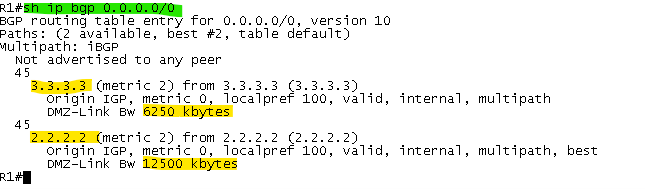
La communauté DMZ-Link permet d’indiquer au routeur R1 la bande passante des sorties Internet afin d’en tenir compte dans les mécanismes de partage de charge du BGP (multipath)

Pour vérifier le bon fonctionnement des mécanismes de partage de charge avec la fonctionnalité Link Bandwidth MultiPath, nous allons mettre en place des ACLs de monitoring sur les routeurs R2 et R3 qui vont juste comptabiliser le nombre de paquets reçus en provenance du routeur R1 et à destination de l’Internet représenté par 45.45.45.45/32.
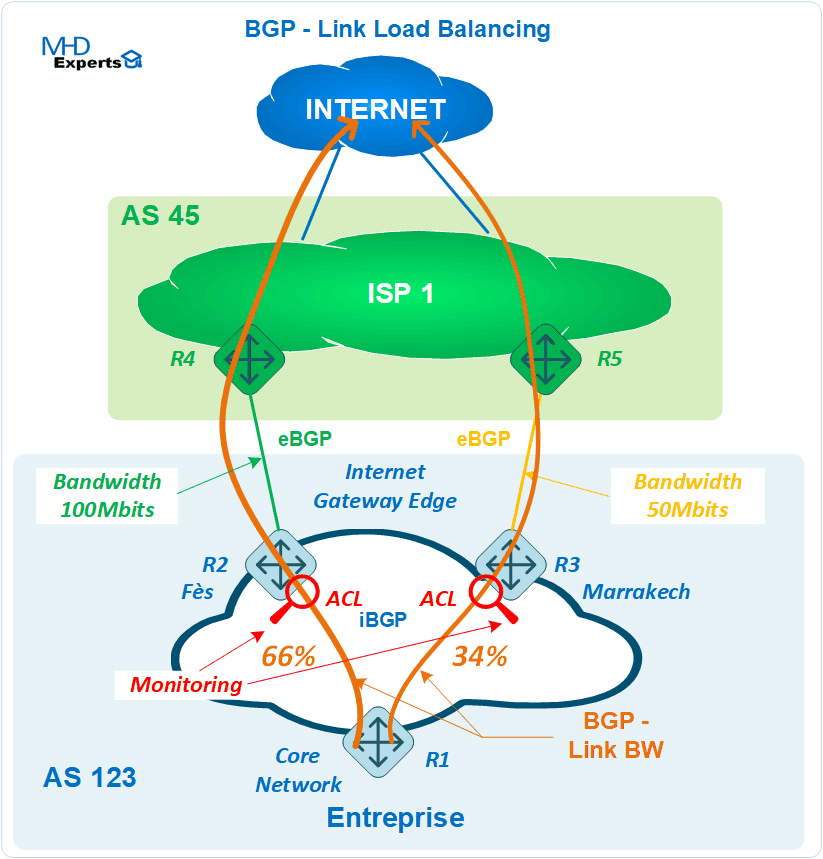
R2 et R3 :
access-list 100 permit ip any host 45.45.45.45 log-input
access-list 100 permit ip any any
!
interface FastEthernet0/0
ip access-group 100 in
Sur le routeur R1, CEF (Cisco Experess Forwarding) nous indique que les mécanismes de partage de charge sont bien implémentés :

Cependant, par défaut, les mécanismes de partage de charge en CEF sont basés sur la destination IP « per-destination distribution », comme on a une seule destination dans notre exemple (45.45.45.45), CEF va toujours utiliser la même interface de sortie.
Pour mieux visualiser la répartition des flux, nous allons dans le cadre de ce test configurer CEF pour faire du partage de charge par paquet « per-packet distribution« , Attention : cette fonctionnalité ne doit pas être activer sur la production sans mesurer les conséquences :
R1 :
interface FastEthernet0/0
ip load-sharing per-packet
interface FastEthernet0/0
ip load-sharing per-packet
Nous allons maintenant lancer 100 pings depuis R1 vers Internet (45.45.45.45/32) et vérifier la répartition des pings sur les deux sorties R2 (100 Mbits) et R3 (100 Mbits) :

Il suffit maintenant de vérifier le nombre de paquets journalisé par l’ACL définie précédemment :


Et voilà ! l’objectif partage de charge est atteint et la preuve est mathématique :
- Deux tiers (66/100) des pings ont été redirigés vers la sortie R2 disposant d’un débit de 100 Mbits.
- Un tiers (34/100) des pings ont été redirigés vers la sortie R3 disposant d’un débit de 50 Mbits.
C’est bien joli tout ça, passons aux choses sérieuses maintenant, intéressons-nous à un vrai cas réel de raccordement Internet : une entreprise qui reçoit de son opérateur une seule route par défaut, et qui utilise un Firewall pour se présenter sur Internet avec une seule adresse IP (PAT), quelles sont les limites de cette fonctionnalité ? Quid des flux entrants ?
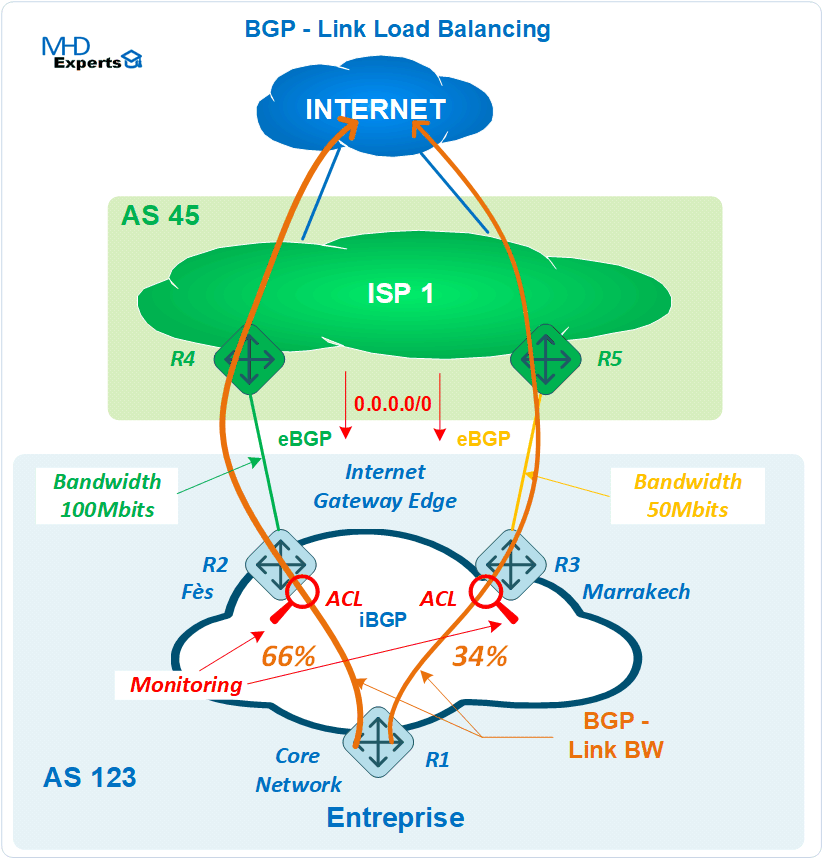
Les mécanismes de partage (iBGP multipath) s’appliquent dans ce cas aussi sur la route par défaut sur le routeur R1 :
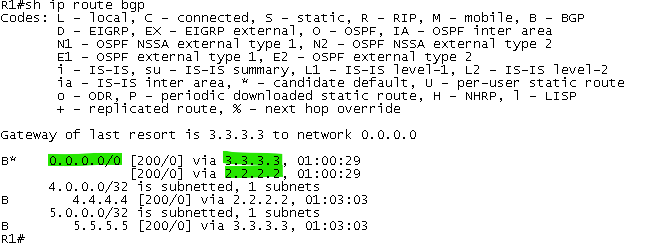
La communauté qui indique la bande passante des sorties Internet est bien transmise aussi au routeur R1 afin d’en tenir compte dans le partage de charge :
Nous allons maintenant générer des flux pour vérifier le bon fonctionnement : depuis R1, nous allons simuler 4 clients qui utilisent la même adresse de sortie pour aller sur Internet 1.1.1.1 (exemple adresse PAT sur un Firewall) et qui vont sur la même destination (45.45.45.45/32), uniquement le port source de la session est modifié (20000 à 20003).
Pour ce faire, nous allons implémenter IP SLA comme indiqué ci-après :
ip sla 1
udp-echo 45.45.45.45 80 source-ip 1.1.1.1 source-port 20000
frequency 5
ip sla schedule 1 life forever start-time now
ip sla 2
udp-echo 45.45.45.45 80 source-ip 1.1.1.1 source-port 20001
frequency 5
ip sla schedule 2 life forever start-time now
ip sla 3
udp-echo 45.45.45.45 80 source-ip 1.1.1.1 source-port 20002
frequency 5
ip sla schedule 3 life forever start-time now
ip sla 4
udp-echo 45.45.45.45 80 source-ip 1.1.1.1 source-port 20003
frequency 5
ip sla schedule 4 life forever start-time now
Pour éviter les effets de polarisation dans CEF et optimiser le partage de charge sur les deux liens, les ports source et destination doivent être pris en compte dans les mécanismes de hashing ECMP :
ip cef load-sharing algorithm include-ports source destination
Vérifions maintenant le partage de charge coté CEF :

Tout est prêt, Il ne reste plus qu’à comptabiliser maintenant le nombre de paquets reçus sur les routeurs R2 et R3 🙂 :


Verdict :
- 136/204 des flux sont redirigés vers R2 pour utiliser la sortie Internet à 100 Mbits soit 66,6666%
- 68/204 des flux sont redirigés vers R3 pour utiliser la sortie Internet à 50 Mbits soit 33,3333%
TADAAA !!!! 🙂
Quid des flux entrants :
Pour ces flux entrants en provenance de l’opérateur, cette fonctionnalité ne s’applique pas car le partage de charge dans ce sens est sous le contrôle de l’opérateur, cependant, les mécanismes habituels de partage de charge dans ce sens restent applicables :
- AS-PATH Prepending ou MED pour signaler à l’opérateur une préférence de traitement sur un lien pour un /24 donné.
- Echange de communauté en BGP avec l’opérateur pour appliquer dynamiquement une politique de routage pour répartir la charge entre les deux liens.(à condition que l’opérateur le supporte)
Autres cas d’usage :
On peut aussi utiliser cette fonctionnalité pour le cas d’une Entreprise qui dispose de deux sorties Internet vers deux opérateurs distincts (ISP1 et ISP2) comme indiqué dans le schéma ci-après :
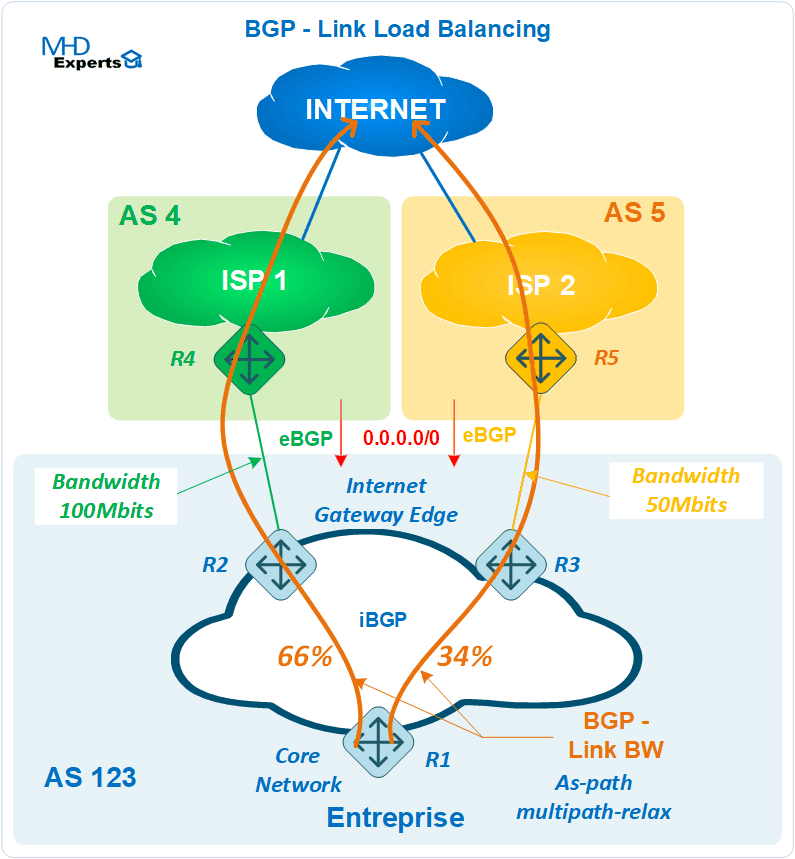
Pleins d’autres cas d’usage de cette fonctionnalité sont possibles, BGP est un protocole robuste et qui propose une multitude d’options pour le trafic engineering. C’est un protocole incontournable dans vos architectures de demain.
En conclusion, cette option de partage de charge est très peu connue et déployée aussi, dans les exemples de cet article on a utilisé la sortie Internet juste pour illustrer et expliquer son fonctionnement, peut être que d’autres cas d’usages sont plus pertinents, si vous avez d’autres idées pour son utilisation ou vous l’avez déjà déployé (hors lab CCIE :)) n’hésitez pas à nous laisser un commentaire pour un meilleur partage.
Si vous avez des questions, des remarques ou vous avez besoin d’un complément d’informations, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter directement à l’adresse : contact@mhd-experts.com.
Zakaria Elqasmi
mai 12, 2020Merci Hicham pour la qualité de l’article, j’ai une question à propos du partage du charge en uplink est-ce que c’est possible ? autre chose est ce que c’est possible de faire une aggregations du débit 100+50?
Hicham TAHRI
mai 12, 2020Merci Zakaria,
Oui, il est possible de le faire aussi en uplink (R2 et R3) dans mon article, il faut pour cela utiliser « maximum-paths eibgp 2 », à tester en maquette ..
Pour un partage de charge encore plus optimisé qui tient compte de latence, bw, etc, il faut envisager des solutions à base de contrôleur (SDWAN ou autres)
Zakaria Elqasmi
mai 12, 2020Merci pour la réponse, ça suppose qu’il y a un lien IBGP entre R2 et R3 ?
Concernant le SDWAN puisqu’il s’agit du service internet c’est du local break out. je n’arrive toujours pas a comprendre comment on va géré le partage ?
Hicham TAHRI
mai 12, 2020Oui absolument, il y a du iBGP entre R2 et R3 pour transmettre la communauté nécessaire pour le BGP MultiPath.
Rabii NOUR
mai 12, 2020Bonjour et Merci ssi hicham pour ce partage constructif.
Hicham TAHRI
mai 12, 2020Merci Rabii !
SAYEL Tarik
mai 14, 2020Bonjour les Amis,
Tout d’abord je remercie l’équipe pour la MES de cette plateforme qui apportera sans doute des éléments de réponse aux networkrs via le partage / échanges avec les différents intervenants.
J’aimerai bien intervenir à propos de ce sujet, car j’imagine que ce cas de figure embête nos clients et implicitement nous embête aussi 😊 :
– LA solution est valable avec la route par défaut, car la majorité des entreprises ne reçoivent pas la table de routage internet Global.
– Généralement (bien sur selon l’activité de l’entreprise) c’est le trafic entrant Download (càd depuis internet vers l’entreprise) qui pose problème vu qu’il est plus conséquent que le trafic sortant, peut-on gérer le partage de charge ?
Merci les amis
Hicham TAHRI
mai 14, 2020Bonjour Tarik,
Merci pour tes commentaires pertinents, j’ai rajouté une section dans l’article pour décrire ce cas et les contraintes aussi, cela permettra d’avoir un meilleur partage avec les gens du réseaux comme nous 🙂
L’exemple Internet est donné à titre d’exemple dans l’article pour illustrer et expliquer le fonctionnement de DMZ BW Link, il y a probablement d’autres cas plus pertinent ..
A+
Hicham
SAYEL Tarik
mai 15, 2020Bonjour Hicham,
Bien dit, c’est la seule méthode aujourd’hui (en tout cas celle que je connais 🙂 ) qui permet de gérer +/- le partage du trafique entrant, je rajoute aussi qu’il s’agit d’un partage de charge manuel ce qui implique de temps en temps une MAJ du poids (AS-Path ou MED) entre les différents segment, car le mois M on arrive a assurer un partage de charge entre un segments S/24 et un autre SS/24, le mois M+2 en pourra se retrouver avec plus d’utilisateurs sous SS que S, donc il faut essayer de s’adapter au fur et à mesure en utilisant des /25…..
Merci
Belaidi Taoufik
mai 17, 2020Bonjour,
Un article bien écrit, et très clair. Merci.
Si je peux résumer le concept, il s’agit de l’exploitation du fait qu’on peut toujours ajouter des attributs à BGP, et que ce nouveau attribut est utilisé comme input dans l’algorithme de hashing qui fait le partage de paquets selon l’information reçue.
Hicham TAHRI
mai 17, 2020Bonjour Taoufik,
Oui, c’est bien le concept, le hashing pour le partage de charge sur les liens tient compte d’une communauté BGP qui indique un poids à prendre en compte.