

Dans ce troisième et dernier article consacré au choix du protocole de routage de la couche Underlay de la Fabric VxLAN/EVPN, nous allons nous intéresser maintenant au protocole eBGP qui permet d’éliminer un grand nombre de contraintes rencontrées en iBGP (voir article 2 pour plus de détail).
L’utilisation du eBGP en IGP dans les Datacenters est née en 2012 (Petr Lapukhov) avec les Hyper Scalers (Amazon, Microsoft, Facebook, Linkedin, ..) qui hébergent plusieurs centaines de milliers de serveurs, les motivations de ce choix de conception sont décrits dans la RFC 7938 « Use of BGP for Routing in Large-Scale Data Centers ».
On distingue deux modèles d’architecture pour l’utilisation du eBGP en IGP pour une Fabric VxLAN/EVPN :
Modèle 1 : Same AS on all Spines, Same AS on all Leafs :
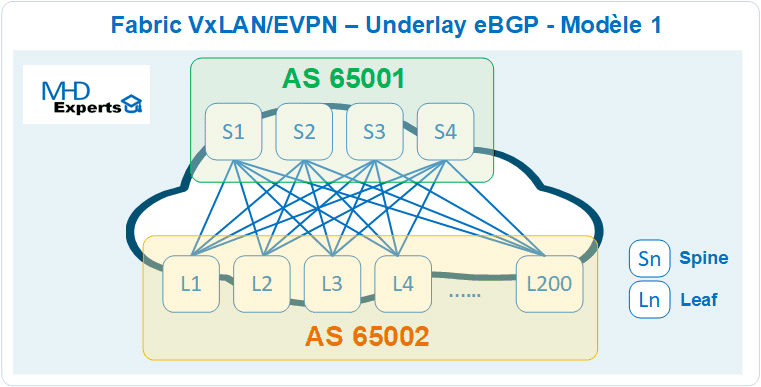
Dans ce modèle d’architecture, seulement deux AS BGP sont utilisés pour les fonctions Underlay et Overlay de la Fabric :
- Un AS 65001 pour l’hébergement des quatre Spines (S1, S2, S3 et S4)
- Un autre AS 65002 pour l’hébergement des 200 Leafs (L1,L2, …L200)
- Implémentation du protocole eBGP entre les AS 65001 et 65002.
- Chaque Spine établit 200 sessions eBGP vers les Leafs.
- Chaque Leaf établit quatre sessions eBGP avec les Spines
- Soit au total 800 sessions eBGP sont nécessaires dans l’architecture pour annoncer les 2 loopbacks sur chaque Leaf qui vont permettre l’établissement de l’Overlay en EVPN.
Modèle 2 : Same AS on all Spines, Different AS on all Leafs :
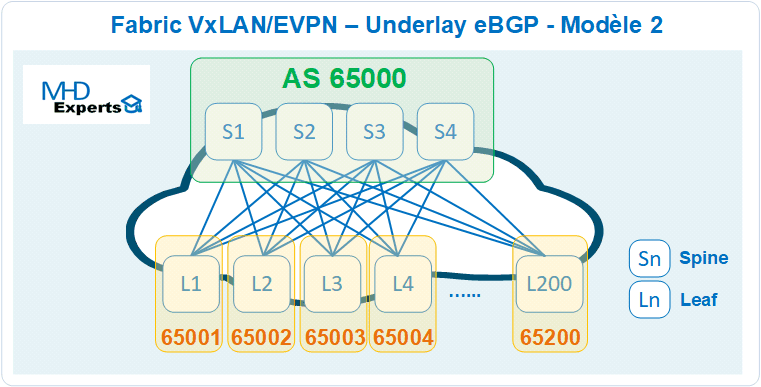
Dans ce modèle d’architecture BGP, plusieurs AS sont utilisés pour les fonctions Underlay et Overlay de la Fabric :
- Un AS 65000 pour l’hébergement des quatre Spines (S1, S2, S3 et S4)
- Chaque Leaf dispose d’un AS unique (Exemple L1 : 65001, L2 : 65002, …L200 : 65200)
- Implémentation du protocole eBGP entre les AS 65000 et les AS des Leafs AS 65NNN.
- Chaque Spine établit 200 sessions eBGP vers les Leafs.
- Chaque Leaf établit quatre sessions eBGP avec les Spines.
- Soit au total 800 sessions eBGP sont nécessaires dans l’architecture pour annoncer les 2 loopbacks sur chaque Leaf qui vont permettre l’établissement de l’Overlay en EVPN.
Configuration :
Leafs : pour les deux modèles, les relations d’adjacences eBGP sont identiques sur tous les Leafs (vers les Spines) et sont définis manuellement dans la configuration, cependant chaque Leaf doit annoncer ses propres loopback (lo1 et lo2).
Spines : pour les deux modèles, il faut déclarer une à une toutes les relations d’adjacences BGP avec les 200 Leafs, l’utilisation des templates « peer-group » permet de réduire considérablement les lignes de configuration à exécuter pour le modèle 1, cependant, la déclaration du voisin BGP reste statique (adresse IP et numéro AS du voisin) contrairement aux protocoles Link State (OSPF et IS-IS) qui permettent l’auto découverte et établissement automatique des adjacences entre voisins.
=> Certains constructeurs proposent aussi la fonctionnalité « Dynamic neighbors » qui consiste à mettre le démon (daemon) bgp en mode « écoute passive» afin d’établir dynamiquement les sessions en provenance des clients, cette fonctionnalité peut être très utile sur les Spines car elle réduit considérablement les lignes de configuration à exécuter, elle doit cependant être sécurisée (acl, password, max sessions) pour éviter des sessions indésirables ou déni de service.
=> Cisco ne permet pas la découverte automatique du numéro de l’AS BGP du voisin.
=> Arista et Cumulus permettent la découverte automatique de l’AS BGP voisin sur les Spines.
=> A noter que les Draft (BGP LLDP Peer Discovery, BGP Neighbor Discovery) traitent ce point, il s’agit de permettre aux voisins BGP de s’auto découvrir et établir les sessions automatiquement.
Contrainte 1 : le nombre de sessions eBGP est important et hormis certains constructeurs (ex Cumulus Network, Arista), plusieurs lignes de configurations sont souvent nécessaires à déployer sur les équipements (surtout Spines) pour établir une à une toutes les relations d’adjacences eBGP.
BGP Path loop detection :
Dans le modèle 1, les mécanismes de détection de boucle native en BGP vont s’activer dans cette architecture pour deux raisons :
- Les Spines vont bloquer l’annonce d’un préfix en provenance d’un Leaf de l’AS 65002 vers un autre Leaf dans le même AS (chez Cisco).
- Les Leafs vont rejeter les annnonces BGP en provenance des Spines et contenant leur AS d’appartenance configuré aussi sur les autres Leafs. (BGP path loop detection)
Pour y remédier, il faut désactiver ces mécanismes de détection de boucle qui constituent une brique importante de la fiabilité en eBGP :
- Désactiver le « peer AS check » sur les Spines « disable-peer-as-check » (Cisco)
- Autoriser l’AS dans l’annonce BGP au niveau Leaf « allowas-in » (ou faire un as-override sur les spines)
Contrainte 2 : Désactivation dans le modèle 1 des mécanismes de détection de boucle sur le protocole BGP (PATH Loop detection) pour permettre l’accessibilité des nexthop sur les Leafs, ce qui peut créer des problèmes de stabilité de la Fabric en cas de boucles réseaux sur les couches Underlay et l’Overlay. On a désarmé le protocole eBGP d’une de ses fonctionnalité les plus importantes.
Cependant cette contrainte ne s’applique pas au modèle 2.
ECMP :
Par défaut, BGP n’annonce et n’installe que le meilleur chemin (BGP Path Selection), pour permettre l’utilisation de tous vos liens (40G/100G) et équipements de la Fabric, il faut activer la fonctionnalité eBGP Multipath (ECMP).
Contrainte 3 : Contrairement au protocoles Link State (OSPF, IS-IS), BGP n’implémente pas nativement l’ECMP, il faut l’activer manuellement dans les configurations eBGP.
Overlay :
L’implémentation de plusieurs AS BGP pour le routage Underlay de la Fabric apporte plusieurs contraintes importantes sur l’architecture Overlay (EVPN) :
- Pour permettre l’établissement des sessions eBGP EVPN à travers des interfaces loopback, il faut activer la fonctionnalité (ebgp-multihop) sur les Leafs et Spines.
- Dans une architecture VxLAN/EVPN, les Spines ne sont pas VTEP, ils n’implémentent pas les VNIs (L2VNI et L3VNI), pour leur permettre de relayer ces informations entre les Leafs, il faut activer la fonctionnalité (retain route-target all) en EVPN sur ces Spines (exactement comme sur les ASBR dans une architecture MPLS inter-AS option B).
- En eBGP, le nexthop n’est pas conservé entre les AS, ce fonctionnement par défaut pose un problème pour l’architecture EVPN : le Spine ne doit pas être terminaison du tunnel VxLAN, par conséquent le next-hop ne doit pas être changé dans les annonces EVPN en provenance des Leafs (implémentation de route-map sur les Spines avec un set ip next-hop unchanged)
Contrainte 4 : la multiplication des AS introduit des contraintes importantes sur le fonctionnement de l’Overlay (BGP EVPN) de la Fabric.
VNI :
Dans une architecture VxLAN/EVPN, la construction des VNI se base (entre autres) sur le principe d’import/export de route-target en EVPN, il faut qu’ils soient identiques pour permettre d’implémenter le segment VNI sur la Fabric. (comme en MPLS L3VPN)
Pour simplifier l’exploitation et la gestion de ces VNI, Cisco permet de les générer automatiquement à partir du numéro d’AS, or dans le modèle 2, chaque Leaf dispose d’un AS différent, donc un RT différent des autres Leafs, par conséquent, les communications au sein du même VNI ne seront pas possibles.
La solution chez Cisco consiste à réécrire le RT (rewrite-evpn-rt-asn) dans le message BGP UPDATE reçu par le voisin, ce qui permettra de maintenir la connectivité de bout en bout du VNI, cette opération doit être réalisée sur l’ensemble des équipements de la Fabric (Leaf & Spine).
D’autre constructeurs ne proposent pas la génération automatique des RT et les configurent manuellement, ce qui est fastidieux en exploitation et impose une solution d’automatisation.
Contrainte 5 : pour le modèle 2 , la multiplication des AS introduit des contraintes importantes sur la génération automatique des RD/RT, Cisco permet de lever cette contrainte par la réécriture des RT, cependant, pour certains constructeurs, il faut saisir manuellement l’ensemble des RT/RD, ce qui complexifie la configuration.
En conclusion, les deux modèles eBGP présentés dans ce document sont valables techniquement, certains constructeurs préconisent le modèle 1 tandis que d’autres vont préconiser le modèle 2.
Personnellement, j’écarterai le modèle 1 (Same AS on all Spines, Same AS on all Leafs ) car il nécessite de désactiver une des fonctionnalités les plus importantes du protocole BGP (path loop detection), ce qui peut avoir des impacts indésirables sur la Fabric en cas de présence de boucle de routage BGP. Je pense que c’est une fonctionnalité très critique qui a permis de rendre protocole BGP très stable (élimination des boucles de routage).
Le modèle 2 (Same AS on all Spines, Different AS on all Leafs) permet de conserver le fonctionnement par défaut du protocole BGP avec ses mécanismes de protection anti-boucle, mais la multiplication des AS introduit des contraintes supplémentaires dans la configuration, la gestion et l’exploitation au quotidien, il faut toujours s’assurer de l’unicité des AS dans le cas de déploiement de nouveaux LEAFs et peut être envisager des AS sur 4 octets dans le cas de Large Fabric (> 1023 Leafs).
Le modèle 2 introduit aussi des contraintes importantes sur la partie Overlay (EVPN) dans la gestion des RT/RD, certains constructeurs proposent de les configurer manuellement ce qui peut être fastidieux et compliqué dans la gestion et exploitation au quotidien, d’autres constructeurs comme Cisco permettent de le générer automatiquement mais de le réécrire dans les échanges BGP updates pour garantir la connectivité du VNI de bout en bout. L’exploitation et la résolution d’incidents ne sont pas évident dans ce cas : un même RT est réécris deux fois (Spine et Leaf).
L’automatisation permet cependant de simplifier les configurations dans les deux cas, elle est très recommandée pour le déploiement d’une Fabric VxLAN/EVPN. (quelque soit l’Underlay utilisé)
Je pense aussi que l’utilisation du eBGP en IGP dans les DC était préconisé pour répondre à une problématique liée aux environnements DC hyper scalers : hébergement de plusieurs centaines de milliers de serveurs dans un DC. Pour ces environnements qui restent très spécifiques et qui utilisent un nombre très important de switchs et de liens inter-switch, les protocoles Link state (OSPF et IS-IS) ont été écartés car le flooding serait assez important (chaque flood entraine un SPF RUN sur l’ensemble des équipements).
Beaucoup personnes et d’experts avec qui j’ai échangé pensent aussi qu’il faut mettre eBGP en Underlay pour la Fabric parce que (Facebook, Google, Microsoft, Linkedin) l’ont fait avec succès, sauf que le cas d’usage de ces hyper scalers est totalement différent d’une Fabric VxLAN/EVPN pour Entreprise : (300 000 serveurs contre 30 000 serveurs soit un ratio de 10)
- eBGP est utilisé en Underlay chez (Facebook, Google, Microsoft, Linkedin) pour permettre le routage de plusieurs centaines de milliers de serveurs : chaque TOR de 48 ports est passerelle par défaut d’un sous réseau (/26 en général) puis annoncé en eBGP dans la Fabric.
- L’Underlay dans une Fabric VxLAN/EVPN en Entreprise est utilisé seulement pour permettre le routage de quelques Loopback par Leaf (2 ou 3) afin de construire le réseau Overlay, ce dernier implémente MP-BGP EVPN pour l’annonce des sous-réseaux serveurs (MAC et IP).
Pour une Fabric VxLAN/EPVN avec un nombre de Leaf < 200, je préfère personnellement créer une séparation entre les couches Underlay et Overlay, l’Underlay est généralement simple à déployer et à configurer avec des gestes d’exploitation très minimes, ce réseau est configuré une fois puis oublié.
Pour ne pas aussi mettre tous les œufs dans un même panier avec un seul protocole (BGP) et apporter une simplification de l’architecture en créant une séparation des fonctions entre les informations d’accessibilité « reachability » et politique des services « service policy », je pense qu’il est plus simple de laisser un IGP (OSPF ou IS-IS) pour la couche Underlay (Reachability), et BGP (EVPN) pour la couche Overlay (Policy), les protocoles Link State permettent aussi de fournir à un contrôleur SDN une vision topologique de la Fabric afin d’y appliquer une politique spécifique aux services (QoS, traffic Engineering, Filtrage, …).
Underlay : OSPF/IS-IS : architecture très simple et très rapide permettant de garantir la connectivité entre les Leafs (VTEP)
Overlay : BGP (EVPN) : commutation et politique routage des services (L2VPN, L3VPN, Firewalls, SLB, …)
Enfin, si ces arguments ne vous ont pas convaincu et que vous préférez quand même faire comme (Facebook, Google, Linkedin), sachez que ces derniers sont entrain de remplacer leur BGP en Underlay par d’autres protocoles (très proche des link-states pour certains) parce qu’avec l’avènement du SDN, ils se sont rendu compte que BGP apportait beaucoup de complexité en mixant les informations d’accessibilité et politique des services en un seul protocole :
Facebook : Open/R (Open routing for modern networks)
Linkedin : Openfabric (une modification du protocole IS-IS pour les Fabric Large Scale)
Google : Firepath (protocole propriétaire avec un fonctionnement proche de link-state)
Si vous avez des questions, un autre avis sur le sujet ou vous avez besoin d’un complément d’informations, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter directement à l’adresse : contact@mhd-experts.com.
Andjib IBRAHIM
juillet 15, 2020Excellente trilogie 😉
Hicham TAHRI
juillet 15, 2020Merci Andjib !!
Quel Underlay pour ma Fabric Leaf & Spine ? (partie 2) – MHD Experts
août 16, 2021[…] la partie 3 de cette série, nous allons étudier le protocole eBGP en configuration Underlay de la Fabric […]
DJIMGOU Serge
novembre 13, 2022Excellent post Hicham, mais si je peux me permettre mais dans le cas de l’utilisation de BGP au niveau underlay, il ya le cas de figure avec EBGP avec chaque spine et chaque leaf ayant un AS different
Hicham TAHRI
janvier 4, 2023Merci Serge, ce cas est traité dans le modèle 2 : Same AS on all Spines, Different AS on all Leafs