
Une infrastructure réseau en Datacenter (DC) a pour mission principale d’héberger les applications SI de l’Entreprise, ces dernières se sont multipliées au cours de la dernière décennie avec des exigences et des contraintes très différentes du modèle traditionnel client-serveur, par conséquent, ces changements ont un impact très important sur la conception des réseaux Datacenter de nouvelle génération.
La conception d’un réseau DC de nouvelle génération doit permettre de répondre principalement aux points ci-dessous :
- Point 1 : Offrir des performances optimales avec une résilience maximale aux applications hébergées.
- Point 2 : Permettre une agilité et mobilité des ressources (workloads).
- Point 3 : Permettre d’intégrer facilement dans l’architecture des services avancées tel que l’inspection des flux (FW/IPS), partage de charge (SLB) et autres (proxy, ..).
Les architectures « CLOS Fabric » qui implémentent les protocoles VxLAN/EVPN ont atteint un niveau de maturité très satisfaisant qui leur permet de valider les points 1 et 2, en effet, ces technologies permettent de répondre aux contraintes des flux Est-Ouest et aussi d’optimiser le fonctionnement interne du réseau DC (Fabric) par l’introduction de nouvelles fonctionnalités avancées adaptées pour les besoins du DC (plan de contrôle robuste et éprouvé basé sur du BGP (EVPN), Passerelle distribuée (Anycast Gateway), Réduction du flooding (Arp Suppression/Proxy), …).
Dans cet article, nous allons nous intéresser de près au point 3, en effet, le plus grand défi d’un architecte réseau est d’introduire les services (FW, SLB, ..) dans une architecture DC de nouvelle génération sans impacter ses performances et dégrader son agilité.
Il existe aujourd’hui principalement deux méthodes pour rediriger les flux vers les nœuds de service :
- Méthode 1 : utilisation des métriques de routage (ex cost (OSPF), localpref (BGP) ou statique) pour influencer le routage vers un noeud de service passerelle des workloads (ex FW ou SLB)
- Méthode 2 : implémentation d’une stratégie de routage basée sur des règles pour sur une redirection sélective du trafic (Policy Based Routing ou PBR).
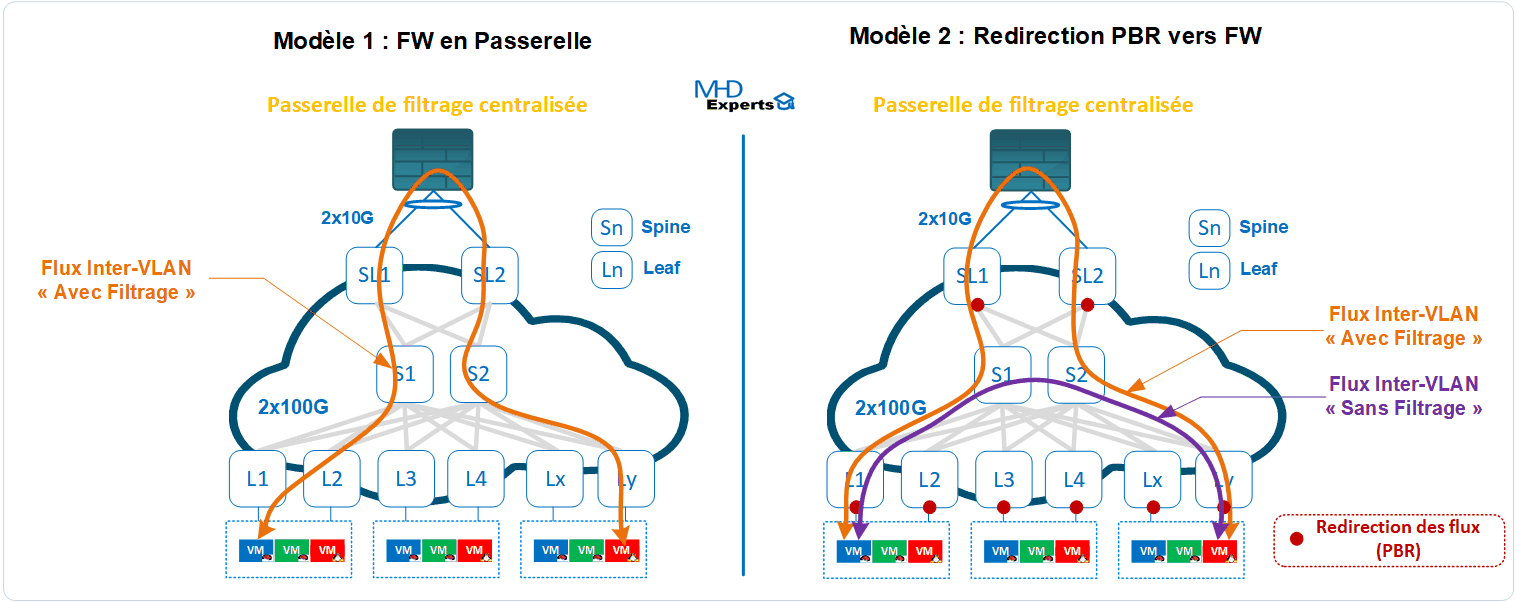
La méthode 1 est la plus courante aujourd’hui dans les réseaux DC, il s’agit d’un héritage des anciennes architectures (Nord-Sud) dont le principe consiste à router les réseaux sur un nœud de service qui se retrouve en coupure (ex FW), la contrainte majeure imposée par ce modèle est que tous les flux doivent emprunter le même chemin et souvent le nœud de service devient un goulot d’étranglement et impacte par conséquent les performances du DC, autrement dit, votre Fabric VxLAN/EVPN disposant de plusieurs liens à 100G/400G se retrouve bridée par le Nœud de Service avec des capacités de traitement réseau largement plus faible.
Pour atténuer ce problème, on installe des FWs très performants en ressources matérielles (CPU, mémoire, interface en 40G/100G ..), ce qui est très coûteux et reste limité par le fait qu’il ne permet pas d’être étendu sur le réseau (principe de passerelle distribuée) : en d’autres terme, on corrige partiellement le problème des performances du réseau par la finance.
La méthode 2 consiste à définir des règles fines (ACL) sur les équipements réseaux de la Fabric afin de rediriger uniquement certains flux vers les nœuds de services (ex FW), cette méthode permet de maintenir les fonctionnalités et performances de traitement réseau et surtout de soulager le FW des traitements dont il n’a pas vraiment besoin d’inspecter (exemple flux de sauvegarde), cependant, elle impose une gestion rigoureuse des règles de redirection et un maintien de la symétrie des flux (flux aller/retour doit transiter par le nœud de service) surtout quand il s’agit d’architecture réseau disposant de plusieurs Leafs avec plusieurs nœuds de service.
Pour simplifier l’implémentation de la méthode 2, les constructeurs réseaux ont apporté des optimisations dans leurs solutions :
- La solution Cisco ACI permet d’apporter une simplification dans l’implémentation de la méthode 2 : un ou plusieurs nœuds de services (FW ou SLB) sont associés aux contrats et le contrôleur APIC se charge de programmer automatiquement le hardware des Leafs concernés par cette redirection (Service Chaining). Merci l’APIC !
- Sur la gamme Cisco Nexus 9K (NX-OS), des optimisations ont également été apporté récemment sur le PBR (Enhanced Policy Based Redirect ou ePBR) et qui permettent de faciliter son implémentation (CLI simplifiée, gestion automatique du flux de retour pour garantir la symétrie, …), cependant, pour les Fabric de taille importante, ces actions doivent être automatisées par l’outil du constructeur ou autres (exemple Ansible).
- Enfin, chez Arista, le contrôleur de la solution (Cloud Visio) permet de s’interconnecter en « native APIs » avec plusieurs nœuds de services leaders du marché ( exemple Fortinet, Palo Alto, Checkpoint, F5), les règles de filtrage sont ainsi apprises et la redirection des flux associée est automatiquement programmée en hardware sur les Leafs concernés. Bien vu CVP !
En conclusion, quelle est la meilleure solution pour intégrer les services (FW, SLB) dans votre DC ? Vous connaissez la réponse : « It depends !! »
En effet, il n’existe pas une solution universelle qui s’adapte à tous les environnements, le choix de la meilleure option va dépendre essentiellement de votre architecture réseau, du matériel utilisé, des technologies utilisées et aussi de votre organisation interne ( exploitation, politique et contraintes de sécurité, ..) :
- le modèle 1 est simple et s’adapte parfaitement pour les environnements qui n’ont pas de contraintes fortes en terme de performances et qui souhaitent reconduire leur modèle de filtrage traditionnel aussi pour les communications serveur à serveur (Est-Ouest), dans ce cas, la Fabric VxLAN/EVPN fournira essentiellement des services de commutation de niveau 2 (L2VNI) car le routage sera porté essentiellement par le FW.
- Le modèle 2 est à privilégier pour les environnements qui souhaitent privilégier les performances et ne pas avoir de goulot d’étranglement lié à l’introduction d’un nœud de service en coupure dans l’architecture, cependant, ce modèle nécessite une ingénierie ainsi qu’une exploitation particulière et doit fortement s’accompagner par une solution d’automatisation pour les Fabrics de taille importante (exemple Arista CVP, Cisco ACI ou Ansible).
On peut aussi citer d’autres solutions que je n’ai pas développé volontairement dans cet article dans un soucis de simplification de la compréhension :
- implémentation de VRF par zone de sécurité avec une politique de filtrage Inter-VRF : dans ce cas, les échanges au sein de chaque VRF sont réalisés par la Fabric sans filtrage (gain en performance) et les échanges entre deux VRFs sont inspectés par le FW installé en coupure.
- Filtrage au plus proche des services par l’implémentation de FW virtuel distribué : cette solution s’appuie sur une solution de virtualisation du réseau qui embarque un commutateur distribué avec des fonctionnalités de filtrage et d’inspection pour interdire ou autoriser les communications entre deux machines du réseau. (forte dépendance avec l’éditeur de la solution et quid de la gestion serveurs physiques ?)
Vous connaissez d’autres options ou vous souhaitez avoir plus détails sur une solution en particulier, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter directement à l’adresse : contact@mhd-experts.com.
Bonne lecture !
Anas
février 21, 2021Très intéressant, Merci Hicham
olivier vallois
mars 9, 2021Je pense qu’il y a une troisieme methode pour adresses les points 1, 2 et 3. Ce sont les SmartNIC. En effet, la performance est au RDV car les operations sont realisees en hardware, et donc on est pas limite par les performances de la CPU du serveur.. Pour le point 2, les politiques de telemetrie, securite, LB sont appliquees sur toutes les cartes en meme temps, ce qui permet une mobilite des VMs. Enfin, pour le point 3, il n’y a pas de traitement particulier du trafic pour l’envoyer vers les appliances car l’appliance est directement sur le chemin du paquet. Les SmartNIC, en tout cas celle que je connais, a savoir HPE SmartIO (Pensando), c’est une appliance materielle distribuee en hardware directement sur le s serveurs. Cela ressemble a la deuxieme solution que vous n’avez pas developpe, a savoir les solutions logicielles embarquees dans les hyperviseurs. Mais contrairement a ces deux solutions, on est pas associe a une diteur d’hyperviseur en particulier et on supporte aussi bien les VMs que le bare-metal et les containers egalement. C’est peut etre une solution a considerer dans les architectures de DC . Aujourd’hui, les acteurs principaux sont Pensando avec HPE, Intel, AMD via le rachat de Xilinx et Nvidia via le rachat de Mellanox. Il y a aussi 2 or 3 autres startups. Cordialement.
Hicham TAHRI
mars 9, 2021Bonjour Olivier,
Merci pour ton commentaire pertinent, La solution SmartNIC parait en effet séduisante et semble répondre aux trois contraintes citées dans l’article, je pense qu’il faudra un article complet (ou webinaire) pour bien la détailler et comprendre son fonctionnement et ses limitations. c’est peut l’avenir des DC de demain ! 🙂
Cordialement
vallois
mars 11, 2021Bien volontiers. Driss m’a propose de faire un webinar pour la communaute mhd-experts. Je prevois aussi de faire un article. Je vois plein d’avantages a l’utilisation des SmartNic pour les fonctions de telemetrie reseau classiques et le filtrage/blocage de flux. La principale limitation est a mon avis le fait que ce sont des solutions jeunes et qui du coup peuvent paraitre limitees par rapport a ce que font les appliances qui ont 5 voire 10 ans de developpement successifs .
Davy MANTE
novembre 6, 2021Super article! Merci Hicham