
Je suis surpris par le nombre d’ingénieurs qui balancent des chiffres exorbitants quand il s’agit du temps de convergence BGP, certes, si on touche pas aux paramètres par défaut du BGP, juste la détéction de la panne par un routeur BGP pourrait atteindre 3 minutes (BGP holdtime 180 secondes) dans quelques scénarios de panne.
Dans cet article, on va parler d’une nouvelle fonctionnalité qui se marie bien avec la solution « BGP Advertise-Best-External » pour réduire le temps de convergence dans une architecture BGP Actif/Passif quand on utilise des Route Reflector. Cette fonctionnalité est connue par le nom de « Shadow Route-Reflector ».
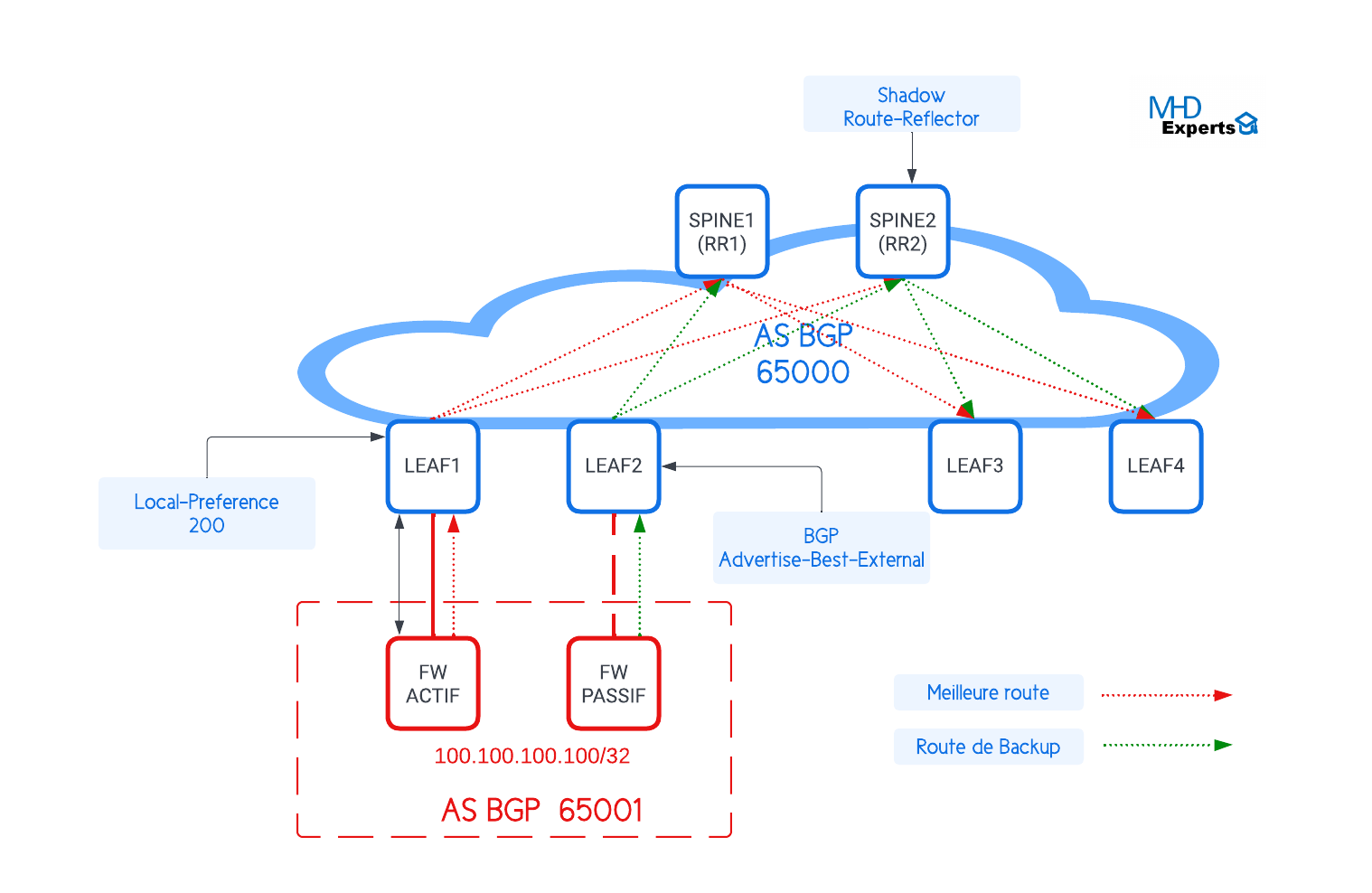
Pour démystifier cette fonctionnalité, on va utiliser pour référence l’architecture ci-dessous :
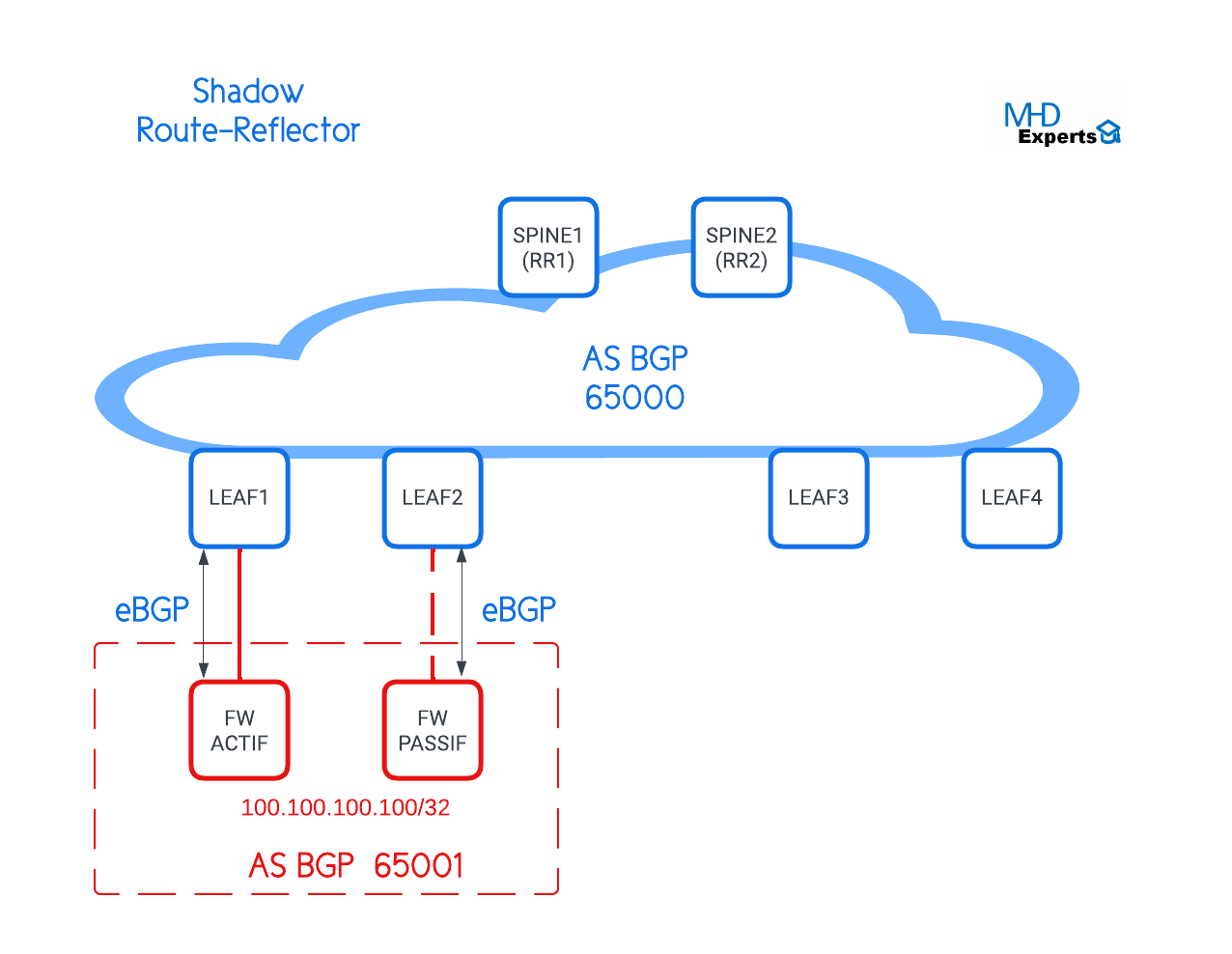
Assumant que notre architecture Leaf & Spine (AS BGP 65000) est connectée à un Cluster de deux Firewalls (AS BGP 65001) en mode Actif/Passif. Afin que le trafic destiné à l’AS 65001 passe en primaire par le LEAF 1 et seulement via le LEAF 2 en cas de panne, on a configuré un « Local Preference » de 200 au niveau de la session BGP entre LEAF 1 et le Firewall ACTIF.
Maintenant, l’AS BGP 65000 ne voit qu’un seul chemin vers l’AS 65001. C’est le chemin via le LEAF 1. Pourquoi nous ne voyons pas le chemin via LEAF 2 ? si vous n’avez aucune idée, je vous propose de voir (cet article)
Lorsqu’il y a une défaillance au niveau de la session BGP reliant LEAF 1 et le FW ACTIF :
- LEAF 1 annonce la perte de la route 100.100.100.100/32 vers les deux Route-Reflectors (RRs) SPINE 1 et SPINE 2 via un message Withdrawal,
- Les deux (RRs) annoncent cette information vers LEAF 2, LEAF 3 et LEAF 4,
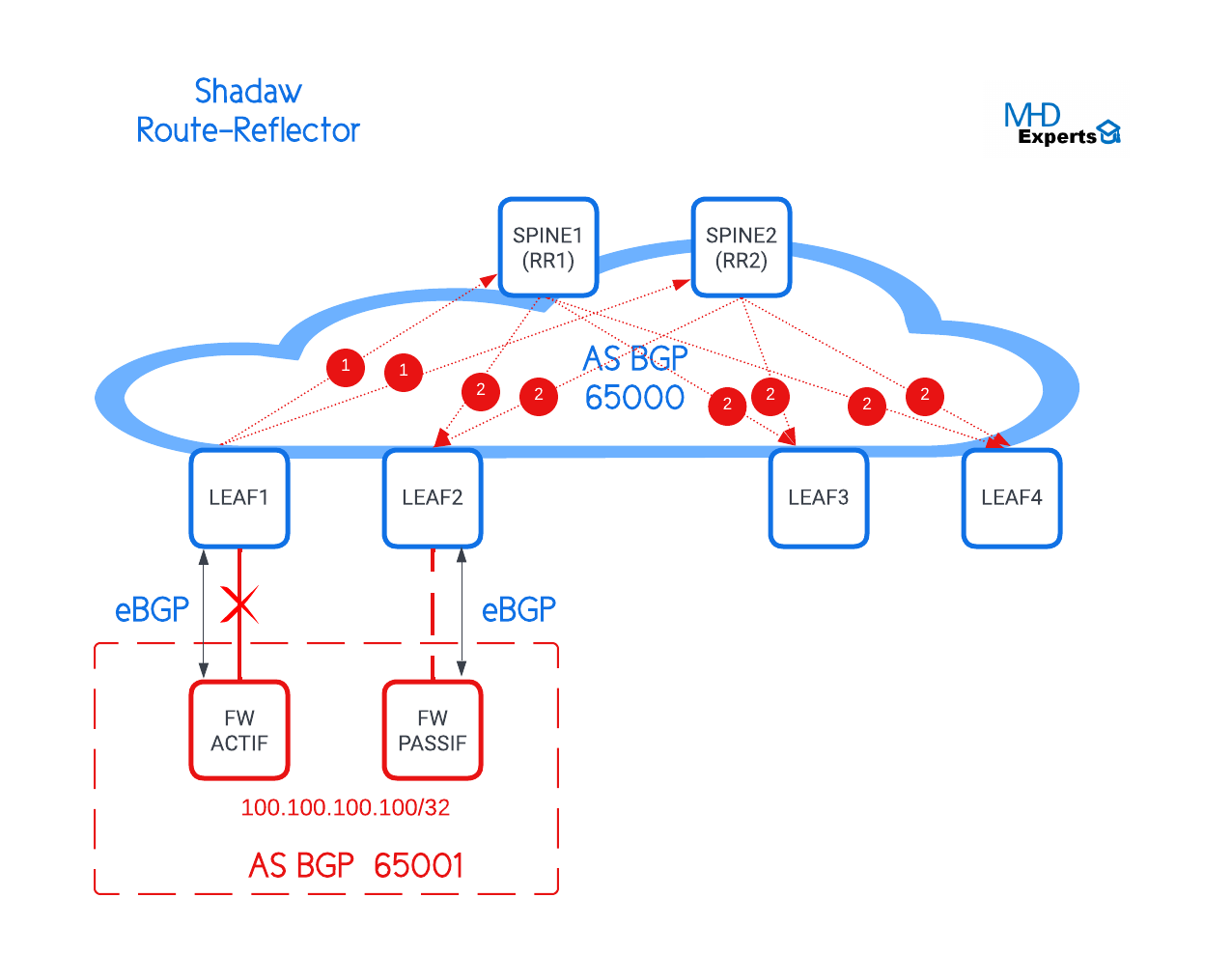
- À la réception du message Withdrawal, LEAF 2 installe la route 100.100.100.100/32 en provenance du Firewall Backup et envoie cette route vers les deux RRs.
- Les deux RRs installent le nouveau chemin dans leurs tables de routage et envoient la mise à jour vers LEAF 3 et LEAF 4.
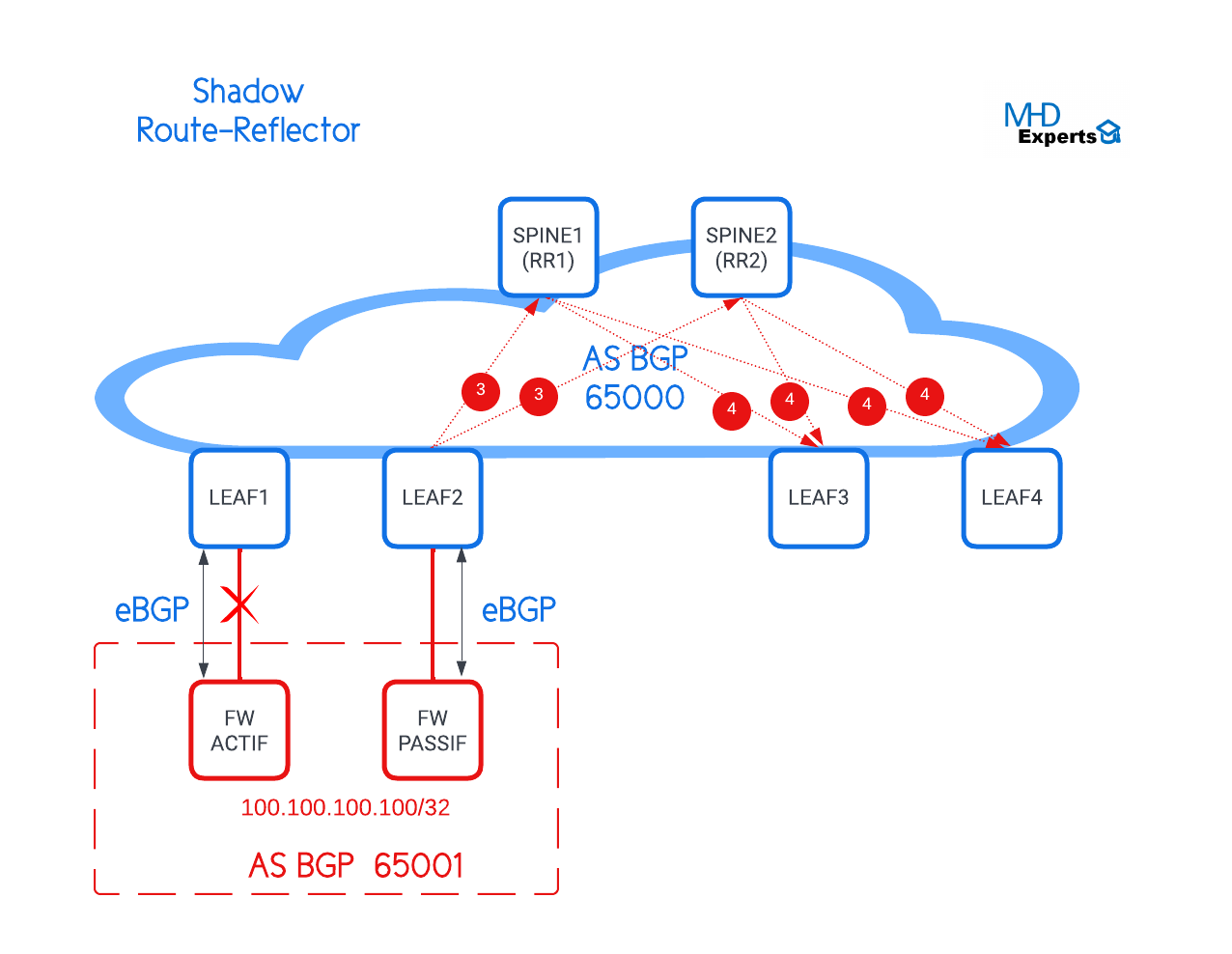
- LEAF 3 et LEAF 4 installent la nouvelle route dans leurs tables de routage. Fin de convergence.
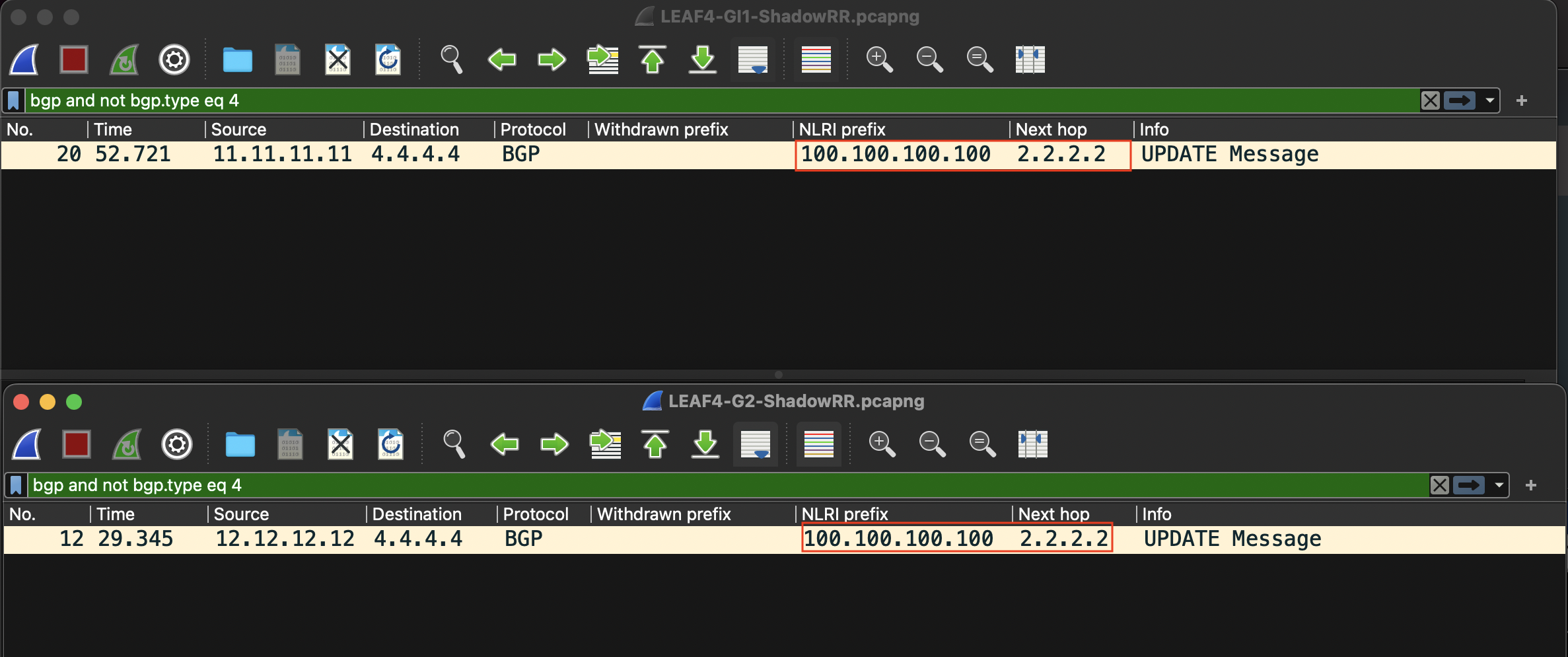
Le temps écoulé entre l’étape 3 et l’étape 4 est de d’environ 28 millisecondes pour la mise jour en provenance du RR1 (11.11.11.11) et d’environ 57 millisecondes pour celle de RR2 (12.12.12.12, ce temps est calculé en capturant les messages BGP au niveau du LEAF 4).
À noter que l’adresse IP 4.4.4.4 est l’IP Loopback du LEAF 4.
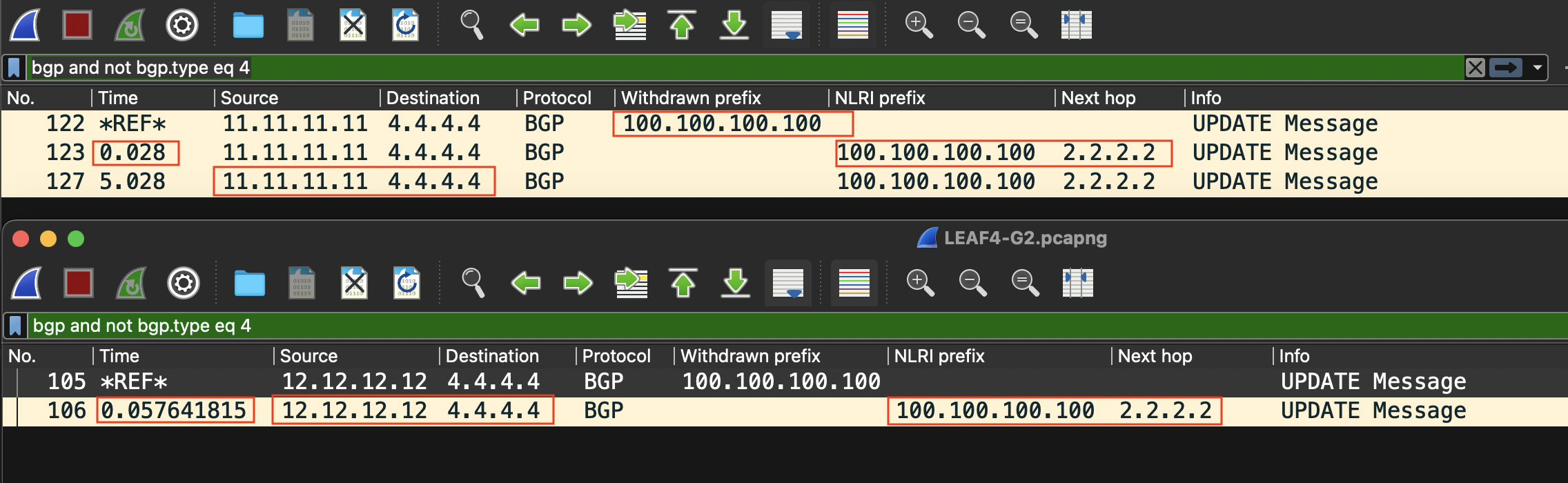
Peut-on faire mieux et optimiser ce temps de convergence qu’est un peu plus de 28 millisecondes si on prend en considération le temps entre la détection de la panne et la propagation du message Withdrawal jusqu’au LEAF 4?
Pratiquement oui, si on arrive à distribuer la route de Backup (via LEAF2) jusqu’au LEAF 4 de telle manière à ce que le LEAF 4 puisse basculer le Next-HOP 1.1.1.1 (LEAF 1) par 2.2.2.2 (LEAF 2) pour rejoindre le subnet 100.100.100.100/32 en cas de coupure du lien LEAF1 <==>Firewall Actif
C’est exactement ce qu’on essayer d’accomplir dans cet article.
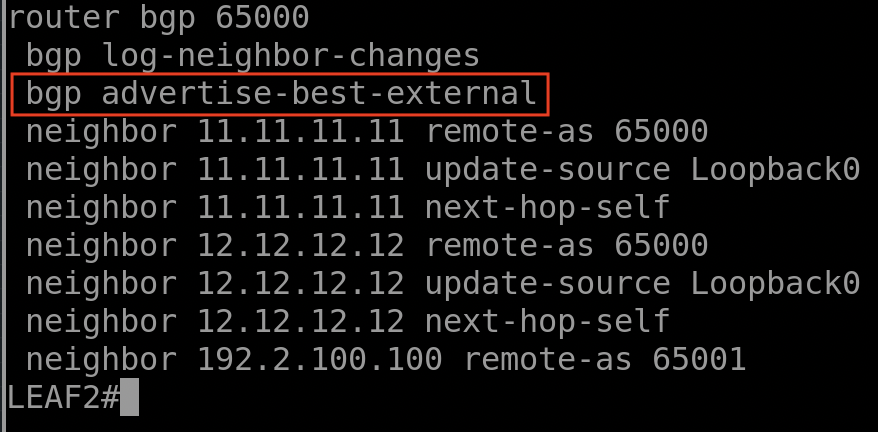
Dans la première étape, on va imposer au LEAF 2 d’annoncer sa route externe 100.100.100.100/32 vers les deux RRs même-ci il préfère la route en provenance du LEAF 1 due à sa valeur Local Preference de 200. Pour cela on va introduire la commande BGP « Advertise-Best-External » dans la configuration BGP du LEAF 2.
Vérifiant tout d’abord, ce que le LEAF 2 annonce aux deux RRs
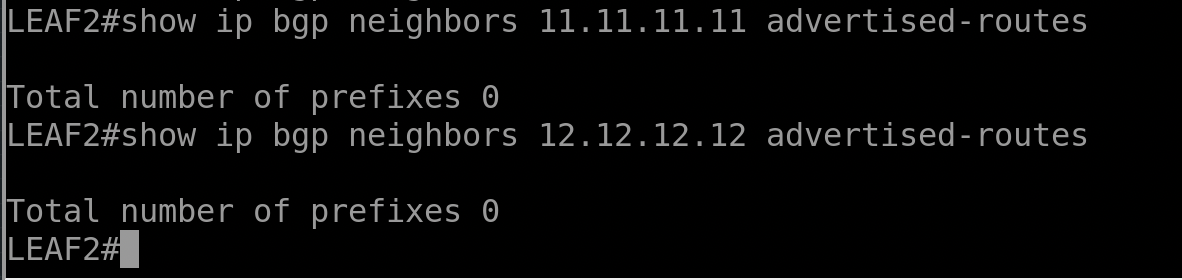
Comme prévu, LEAF 2 n’annonce pas vers les RRs la route 100.100.100.100/32 qu’il connait via sa session eBGP avec le Firewall.
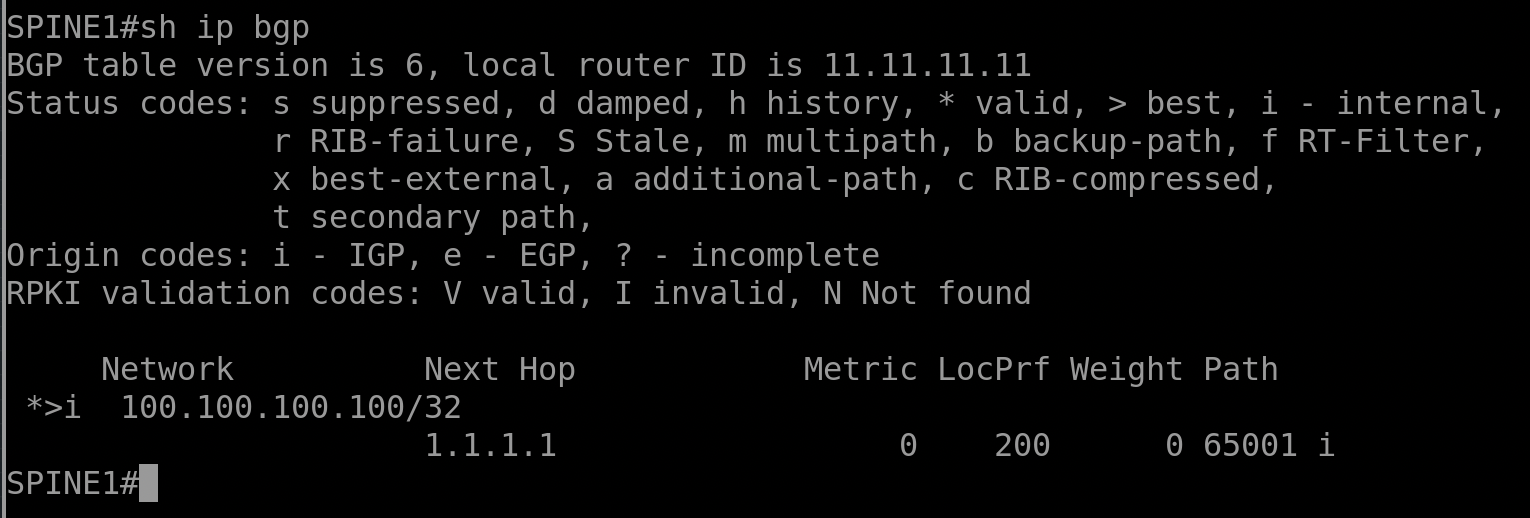
Le SPINE 1 ne voit que la route via le next-hop 1.1.1.1 (LEAF 1).
Introduisant maintenant la commande « bgp advertise-best-external » dans le LEAF 2 :
Maintenant la route via 2.2.2.2 (LEAF 2) est belle et bien présente dans la table RIB des RRs avec un tag « bi » ce qui signifie une route de backup interne.
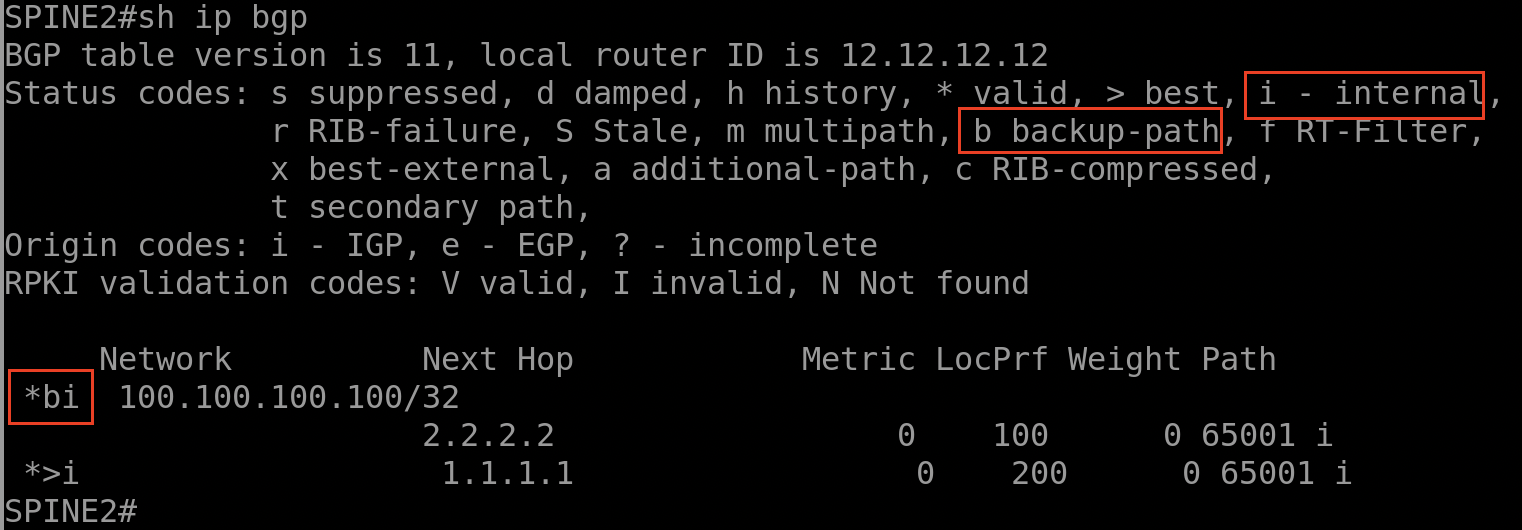
Est-ce que cette route est envoyée par les RRs vers ses clients (LEAF 3, LEAF 4) ?
Malheureusement non, les deux RRs quant à eux, ils n’enverront que la meilleure route vers leurs clients LEAF 3 et LEAF 4, en l’occurrence la route via 1.1.1.1 due à la valeur de sa Local Pref (200).
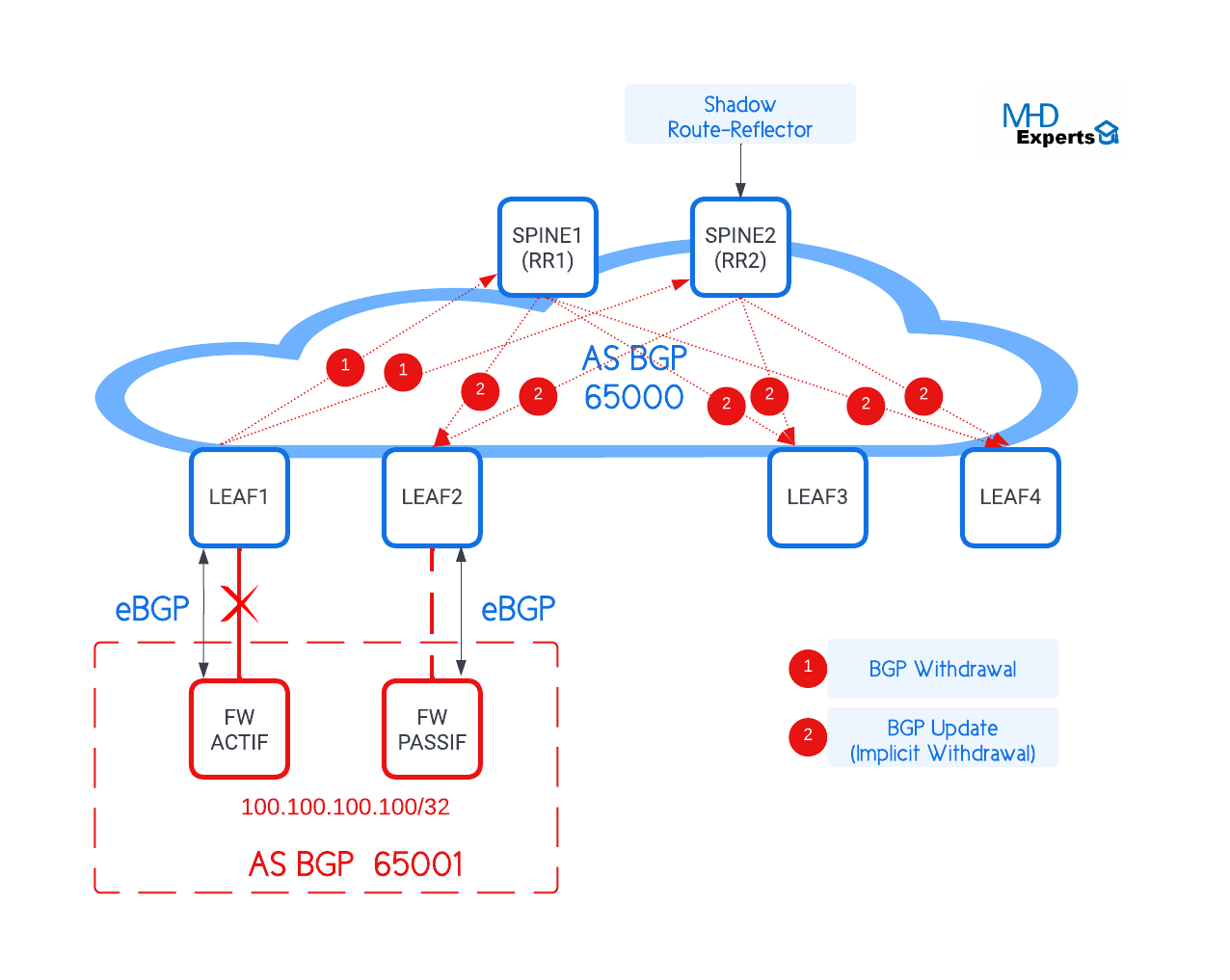
Shadow Route-Reflector (RR):
Et si on demandait au SPINE 2 (RR) d’annoncer sa route de Backup au lieu de sa meilleure route vers le subnet 100.100.100.100/32 ?
Cela signifie que LEAF 3 et LEAF 4 recevront deux routes :
- Une route 100.100.100.100 via Next-Hop 1.1.1.1 par le SPINE 1
- Une route 100.100.100.100 via Next-Hop 2.2.2.2 par le SPINE 2
Le Shadow RR et un RR qui annonce uniquement à ses clients sa route de Backup au lieu de sa meilleure route. Le schéma ci-dessous illustre le principe :
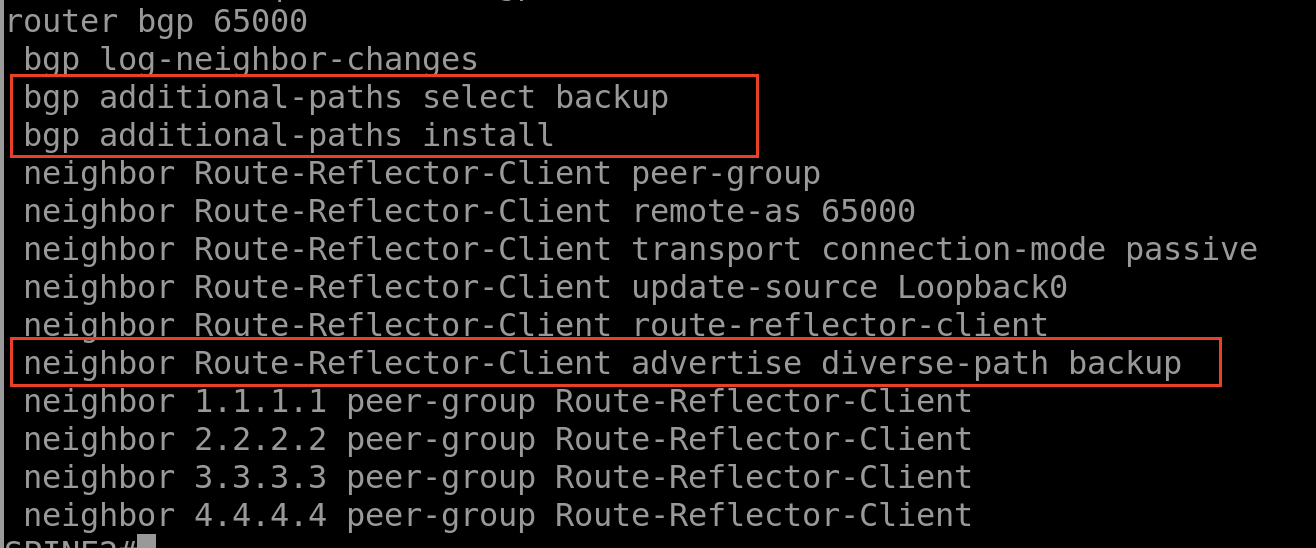
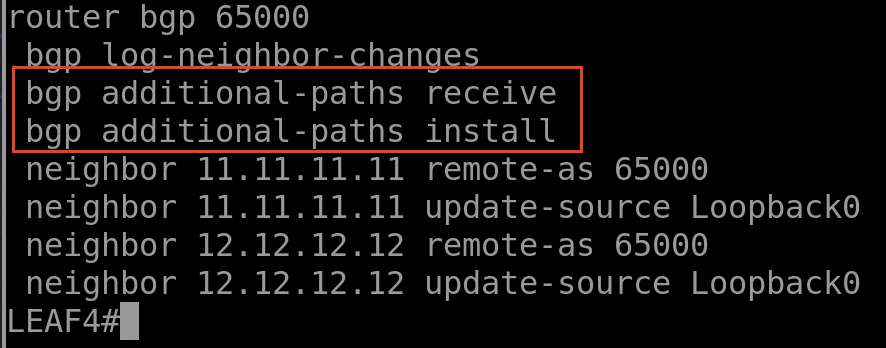
La configuration du Shadow RR :
La commande « BGP additional-path select backup/ bgp additional-path install ==> je demande au SPINE 2 de choisir et installer la route de Backup dans la table RIB, et via la commande « neighboor Route-Reflector-Client advertise diverse-path backup » je demande au RR d’envoyer la route de Backup au lieu de la route primaire.
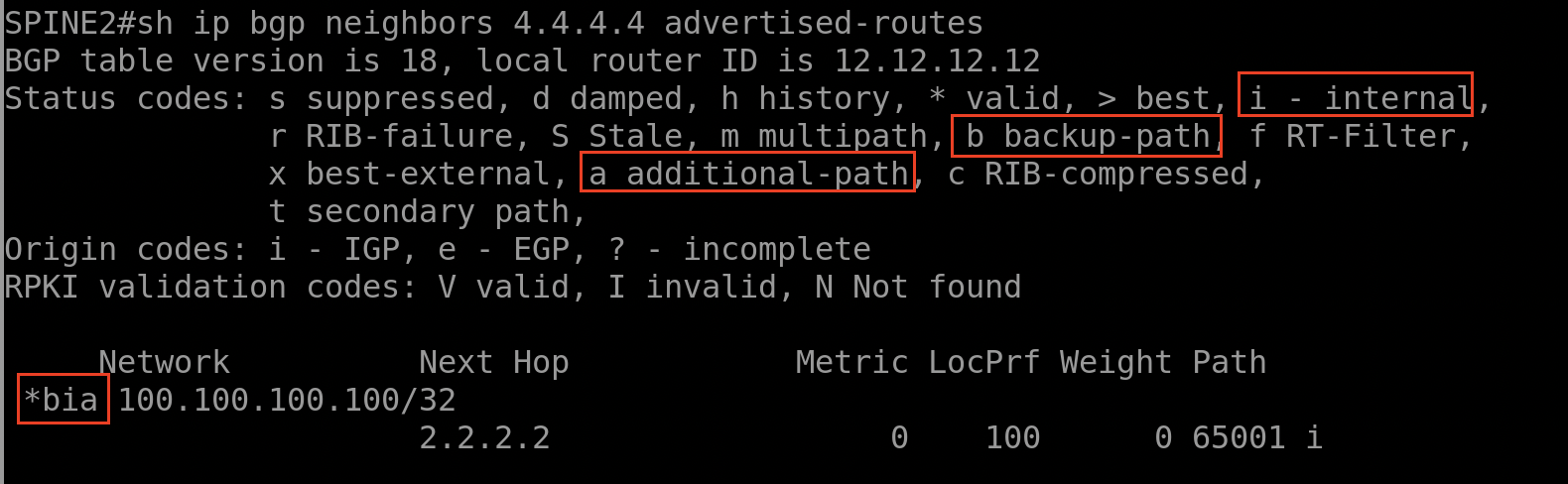
En vérifiant la table BGP du SPINE 2, on voit bien qu’il y’a deux routes vers le subnet 100.100.100.100/32, via le LEAF 1 et aussi le LEAF2 :
Le SPINE2 (RR) annonce sa route backup vers ses clients :
Finalement, je demande au Route-Reflector Client, LEAF 3, LEAF4 d’accepter et d’installer la route de Backup dans la table RIB ainsi dans la table FIB en tant que route de backup
Vérifier la table du routage BGP :
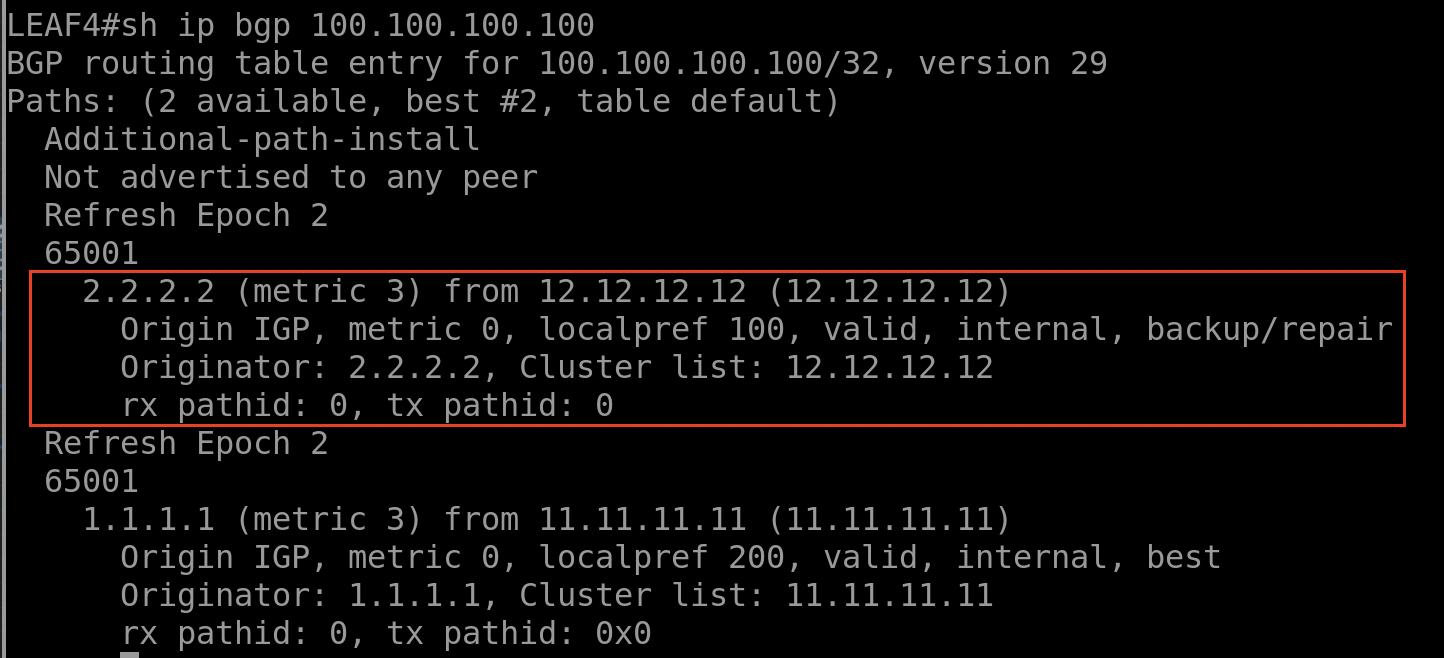
LEAF 4 possède les deux routes dans sa table de routage BGP.
Vérifier la table FIB :
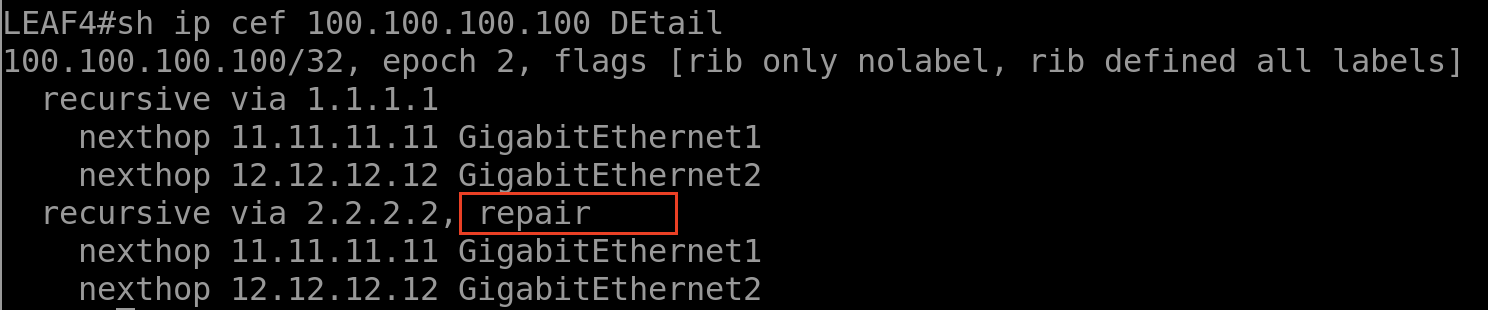
De la même façon, la table FIB contient la route via le 1.1.1.1 (LEAF 1) et la route via 2.2.2.2 (LEAF 2) qui sera utilisée comme Backup.
Maintenant, quand le lien entre le LEAF 1 et le Firewall Actif est coupé,
- LEAF 1 informe les RRs via un message Withdrawal et,
- Les RRs n’envoient pas un Withdrawal vers ses clients mais plutôt une mise à jour en leurs informant que le subnet 100.100.100.100/32 est désormais joignable via 2.2.2.2 (LEAF 2). Cette mise à jour est considérée comme un implicite Withdrawal.
Voici une nouvelle capture du trafic BGP après la mise en place d’un Shadow RR :
Dans cet article, on a vu comment peut-on réduire le temps de convergence du protocole BGP en ayant une route de backup installée dans la table RIB et FIB dans les architectures BGP Actif/Passif ou le Route-Reflector est utilisé. Le Shadow RR nécessite la configuration de BGP Advertise-Best-External et les routes de Backup ne sont envoyées que vers les routes reflector Client. En cas d’absence d’un deuxième RR, on peut utiliser une shadow session, cela nécessite l’établissement d’une session BGP secondaire entre les RR et les RR clients en utilisant des nouvelle interfaces Loopback et utiliser les mêmes commandes qu’on avait appliqué dans le Shadow RR.
Si vous avez des questions ou vous avez besoin d’un complément d’informations ou une consultation spécifique à votre environement, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter directement à l’adresse : contact@mhd-experts.com.
Mehdi SFAR
janvier 17, 2023Merci Driss pour cet article très intéressant et bien écrit 🙂
Le BGP Best External est une importantes composantes du BGP PIC, son seul inconvénient, c’est la consommation de ressources supplémentaires (je suis d’accord que cela pose moins de pb de nos jours)
Juste un commentaire concernant la phrase « la convergence pourrait être longue mais pas 3 minutes quand même »
Les timers BGP par défaut sont de 60 secondes pour les keepalives et 180 secondes (3 minutes) pour le Holdtime.
Certains cas me viennent en tête qui pourraient se baser sur le Holdtime (donc 3 minutes par défaut) pour « détecter » une coupure (sans parler des étapes de propagation Withdraw, recalcul, et MAJ FIB/RIB pour avoir le temps de convergence total qui dépasserait en théorie 3 minutes) :
> Peering entre deux routeurs avec un switch au milieu et une panne sur une des interfaces Switch-Routeur
> Peering entre au moins une SVI d’un switch L3 avec une panne sur un des interfaces, mais la SVI reste UP (le VLAN pourrait être étendu sur un autre port)
> Perte d’un RR (donc d’une Loopback), et le NHT bascule sur une route plus large, voir la route par défaut
> Peering entre deux routeurs, avec une panne sur un SFP qui entraîne que le port reste en état UP (rare, mais cela arrive)
Evidemment, on peut réduire ces temps de détection (et donc convergence globale) en utilisant du BFD, ou en réduisant les timers par défaut…
Je suis sûr que je ne t’apprends rien, c’est plus pour les lecteurs 🙂
A+, Mehdi
driss jabbar
janvier 17, 2023Bonjour Mehdi,
Merci pour ton commentaire instructif, je suis tout à fait d’accord avec toi si on touche pas au paramètre holdtime (180 secondes) par défaut, on peut atteindre 3 minutes juste pour la detection de la panne.
Le BFD est la solution pour la detection de la panne
–> Pour le NHT, ce temps ne depassera pas 60 secondes ( le scan timer) modifiable bien évidement, ou en n’autorisant pas la recursion des host route.
Je vais changer la pharase, j’y pensé à le faire hier mais j’ai oublié.
Merci
Mahi Abdelkader
février 12, 2023Merci Driss pour cet article très intéressant et bien écrit 🙂
j’ai une question si possible ? Si notre equipement HS (actif) est rétabli
comment la session bgp va procéder ?
driss jabbar
février 17, 2023Aprés la rétablissement du RR primaire, il va monter les sessions BGP avec ses clients et il’y aura un recalcul BGP pour choisir la route envoyer par ce RR.
Merci