
Pour un projet stratégique de refonte d’infrastructure Datacenter pour une grande entreprise internationale, j’ai eu l’opportunité (et la chance aussi) de travailler sur le design d’une architecture Leaf & Spine avec les technologies VxLAN/EVPN.
Pour ce projet « Large Scale DC » composé de quelques milliers de switchs Leafs (VTEP) repartis entre plusieurs DC géographiques, l’architecture cible devait garantir la fiabilité, la haute disponibilité du SI, la réduction d’impact clients en cas d’incidents, l’extension au cloud public sans oublier l’automatisation des gestes de configurations et d’exploitation, en résumé : un DC nouvelle génération (NextGen DC).
La fiabilité d’un réseau DC commence d’abord par la fiabilité des équipements réseaux qui le compose (hardware et système d’exploitation), on peut faire les meilleurs choix en terme de design réseau (protocoles, technologies, tolérance aux pannes ..) mais si c’est mal codé ou que le système d’exploitation des équipements réseaux présente des fragilités, toute la fiabilité tombe à l’eau, c’est le premier point très important à sécuriser dans vos choix en terme d’architecture réseau.
Il y a aussi beaucoup de choses à dire sur le design DC de cet envergure comme le choix underlay, overlay, zones de disponibilité, intégration FW/SLB, cloud hybride, déploiement, automatisation, exploitation, les bonnes pratiques, les pièges à éviter, je ferai quelques articles sur ces sujets prochainement dès que le temps me le permettra.
Pour ce projet, Arista Networks a été sélectionné (pour diverses raisons que je ne développerai pas dans cet article) pour le nouveau DC du groupe, dans cet article j’ai envie de partager avec vous en toute objectivité mon premier retour d’expérience sur la solution car dans un récent sondage réalisé sur mhd-experts.com, j’ai constaté que très peu de personnes en France connaissent les produits Arista, pourtant Arista Networks est classé parmi les « Leaders » par les cabinets de conseils en solutions DC exemple « Gartner Magic Quadrant », « Forrester Wave ».
Arista existe depuis 2004 et s’est spécialisé dès le départ sur les infrastructures DC (plus précisément Low Latency dans les milieux financiers), son système d’exploitation EOS (Extensible Operating System) a été pensé et développé pour répondre spécifiquement aux besoins des réseaux DataCenter.
Je pense sincèrement que l’EOS fait partie des points très fort de la solution Arista, s’il faut le résumer rapidement je dirai que l’EOS un « vrai linux » avec une interface de lignes de commandes ( ou CLI) aux normes de l’industrie.
Par « Vrai linux » je veux dire qu’il n’a pas été modifié ni adapté par le constructeur, il est ainsi possible de lancer un bash shell et administrer le switch de la même façon qu’un serveur linux : terminer et relancer des processus, lancer les commandes « top, ps, ls,vi, less,tar, tail, gunzip, vmstat, kill », écrire des scripts, ..
Ce point pour moi est très puissant pour un NOS (Network OS) car il permet d’offrir une flexibilité importante et peut ainsi s’intégrer facilement avec le monde de l’automatisation et ses outils pensés à la base pour des OS comme Linux (exemple Chef, Puppet et Ansible).
Un autre point très fort de l’EOS qui permet de le distinguer de la concurrence est son fonctionnement en multi-agents avec une SysBD, en termes simples, il faut voir la sysDB comme une base de données système sur le switch qui contient tous les états, variables et autres informations importantes publiés par les agents à disposition des autres agents.
Exemple : le protocole STP va publier son état de plan de contrôle (Forwarding ports, Blocking Ports, Root port, ..) dans la base centralisée SysDB, si un autre agent (exemple MLAG) souhaite avoir ces informations, il va les chercher directement dans cette base centralisée, cela permet d’éviter les communications IPC (Inter-Process Communications) qu’on retrouve souvent chez les autres constructeurs.
Le schéma ci-dessous permet d’illustrer la différence de fonctionnement entre Arista EOS et un Legacy NOS en IPC :
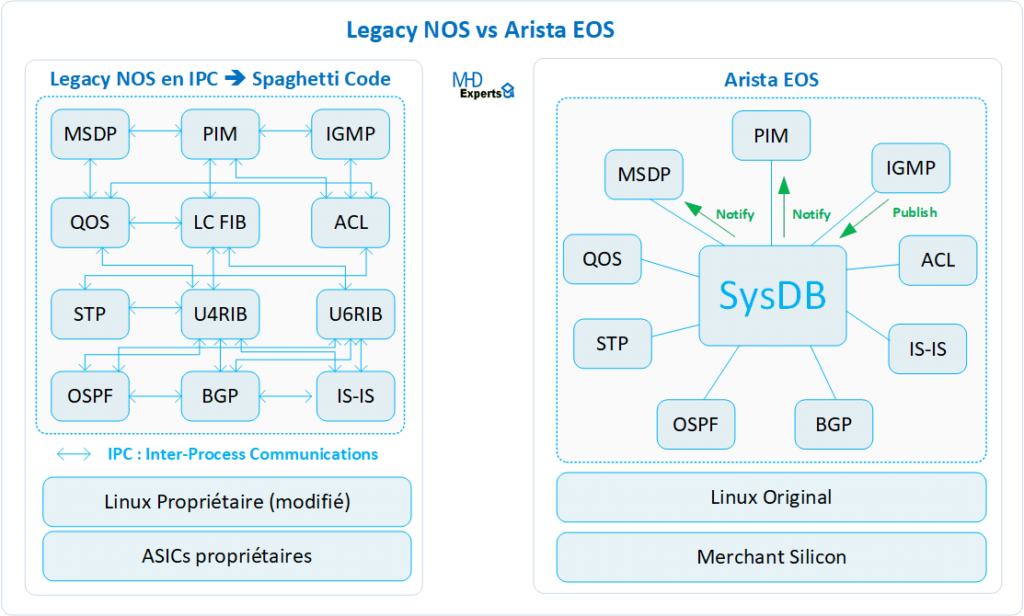
Cette décorrélation entre les « états du plan de contrôle » et les « opérations de traitement » est très importante pour garantir une grande stabilité du système dans sa globalité car il permet de restreindre les potentiels problèmes à un périmètre très restreint n’impactant pas le reste du système.
Prenons un exemple du protocole spanning-tree (ex MST), quand il sera lancé pour la première fois après le redémarrage de l’équipement, il va d’abord passer par les états habituels : Discarding => Learning => Forwarding.
Ces opérations vont prendre un certain temps en exécution puis l’état du protocole MST sera renseigné dans la SysDB pour être à disposition du système.
Imaginons maintenant que le processus STP crash pour une raison inconnue (bug, charge importante, …) quand le processus va redémarrer automatiquement par le process manager (linux), il va d’abords consulter la SysDB pour récupérer son ancien état et aucune convergence ne sera observée du protocole, ce point est un différenciateur important par rapport à la concurrence ou l’état des protocoles n’est pas conservé et nécessite un nouveau calcul avec une convergence (impact sur la disponibilité).
Un autre point important est que tous les commutateurs Arista utilisent la même image EOS quelque soit le modèle (du petit switch au très grand switch), ce qui simplifie considérablement l’exploitation (même CLI sur tous les équipements) : la même image est téléchargée et poussée ensuite sur les milliers d’équipements sans se soucier du modèle ni de la compatibilité de version.
Cette stratégie « Un seul système d’exploitation, Une seule image » permet aussi d’optimiser le développement de nouvelles fonctionnalités ainsi que les correctifs, de simplifier le processus de certifications et de validation du code afin de garantir la fiabilité du logiciel.
Pour résumer, l’EOS d’Arista est parti d’une feuille blanche en 2004 avec une stratégie basée sur la fiabilité pour répondre aux besoins des réseaux en DC, ses principaux caractéristiques sont :
- Un noyau Linux standard et non modifié
- Architecture en multi-agent sans aucune communication directe entre les agents
- Une base centralisée SysDB robuste pour la publication et la consultation des états des agents
- Une abstraction matérielle pour support sur plusieurs types de plateforme
- Implémentation de protocoles standard et interopérabilité multi-constructeurs
En conclusion, cet article permet de donner un bref aperçu sur le fonctionnement interne de l’EOS d’Arista, des différents témoignages que j’ai pu avoir d’autres clients (ex banques/assurance), il est très stable et mature.
Les équipes de développement coté Arista sont aussi très vigilantes sur sa stabilité et sa non régression avec l’ajout de nouvelles fonctionnalités, de mon coté, mon premier retour est positif, je n’ai pas constaté d’anomalie importante pourtant je l’ai bien stressé pendant la phase de tests du projet (large scale (MAC/VLAN/IPv4,IPv6, VRF..), charge importante, ..), je vous en dirai un peu plus dans quelques mois peut être.
Si vous avez des questions, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter à l’adresse : contact@mhd-experts.com
Elisabeth Rodrigues
juin 30, 2022Avec Junos EVO, Juniper Networks propose également un OS sécurisé et ouvert basé sur linux avec une base de données des états 😉
https://www.juniper.net/documentation/us/en/software/junos/overview-evo/topics/concept/evo-overview.html
De plus, Junos EVO bénéficie des avantages proposés par Junos depuis très longtemps : commit confirmed / rollback / Netconf natif / automatisation avancée
Hicham TAHRI
juillet 17, 2022Bonjour Elisabeth,
Merci pour le partage, c’est très intéressant !