
Déployer des services L4/L7 en mode HA dans le Cloud Public représente un vrai défi, tout simplement parce que la plupart des constructeurs des services L4/L7 requièrent un segment niveau2 entre les membres du cluster, un sous-réseau partagé et finalement une IP partagée souvent appelée VIP (Virtual IP) active dans le membre actif du cluster et automatiquement l’utilisation du protocole ARP.
Ces prérequis, ne sont malheureusement pas supportés lorsqu’on songe à déporter cette architecture vers le Cloud Public.
J’étais amené récemment à faire la conception et la mise en place d’un cluster F5 en mode Actif/Passif dans l’environnement Azure. Ma première réflexion, c’était de chercher la solution dans le site du constructeur mais je n’ai rien trouvé. F5, dans son site, affirme belle bien qu’il supporte le mode A/P sans détailler techniquement comment cela fonctionne.
D’une manière générale, quand on cherche à déployer des NVA en mode HA, Azure propose deux solutions :
- L’utilisation des API : le principe est de superviser l’état des membres du cluster et de basculer le routage via des appels API d’un membre à l’autre en cas de Fail-Over. Assurez-vous, vous n’avez pas besoin d’être expert en API pour faire cette manipulation car tous les constructeurs que je connais, mettent à votre disposition la configuration dans leurs répertoires Github. Seul bémol des API Azure, c’est la lenteur d’exécution, Azure utilise un système API global dont les appels API sont exécutés en mode FIFO, le temps de bascule varie entre 30 et 90 secondes, parfois plus long.
- L’utilisation d’un Azure Load Balancer (ALB) : Oui, ce n’est pas une blague, pour assurer le HA de notre Load Balancer F5, Azure propose de les positionner derrière un Load Balancer d’Azure. C’est bien le scénario que j’avais choisi et que je détaillerai dans cet article.
Azure Load Balancer :
L’ALB est un service d’azure évolutif et hautement disponible qu’opère uniquement sur la couche 4 du modèle OSI (Open Systems Interconnection). Il représente le point de contact unique pour les clients, les F5 dans mon cas. L’ALB distribue les flux entrants arrivant sur son IP frontale aux instances du Backend Pool et comme tous les Load Balancer décents, l’ALB a besoin d’une règle qui définit le port sur laquelle l’IP frontale va écouter et rediriger le flux vers le Backend. Un schéma vaut milles mots :
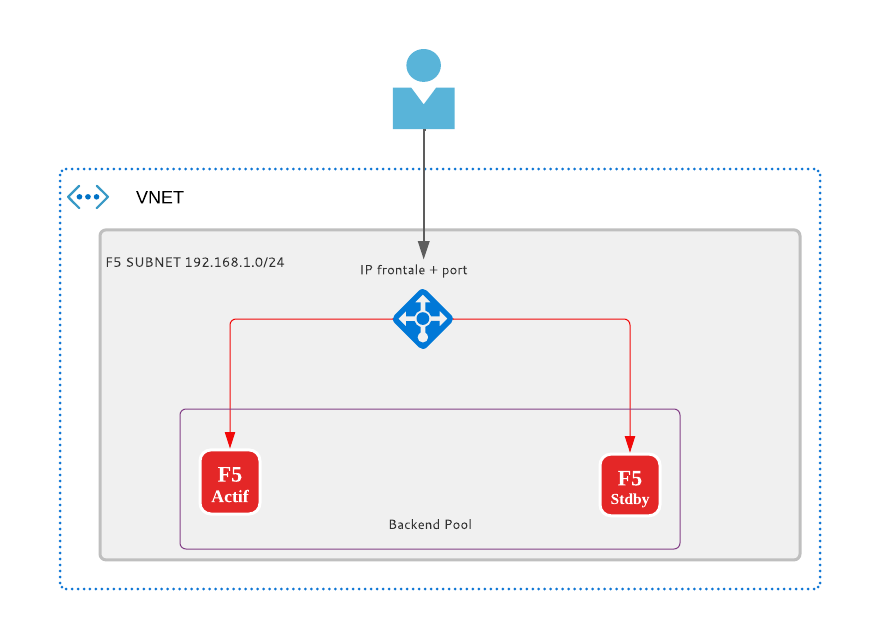
Comment l’ALB détecte l’état de santé de chaque membre de son Backend Pool ?
L’ALB envoie d’une façon périodique des messages de Probing (KeepAlive) vers tous les membres du Backend Pool, les membres qui répondent aux messages de Probing sont considérés actifs et ceux qui ne le font pas sont considérés tout simplement inactifs. L’ALB partage la charge seulement sur les membres actifs. (Tout va bien jusqu’à maintenant).
Note : L’ALB de type standard supporte du Probing de type TCP, HTTP et HTTPs.
En arrivant à ce stade, je pensais qu’en configurant les deux F5 en mode HA Actif/Passif je n’aurai que le FW primaire qui répondait aux Probing (TCP 443) envoyés par l’ALB mais en réalité et contre toute attente, le membre passif répondait lui aussi à ces Probing, par conséquent l’ALB considère les deux F5 actifs et leurs partage la charge. Le flux atteignant le membre F5 actif est traité correctement en revanche celui qui est redirigé vers le membre passif est tout simplement ignoré.
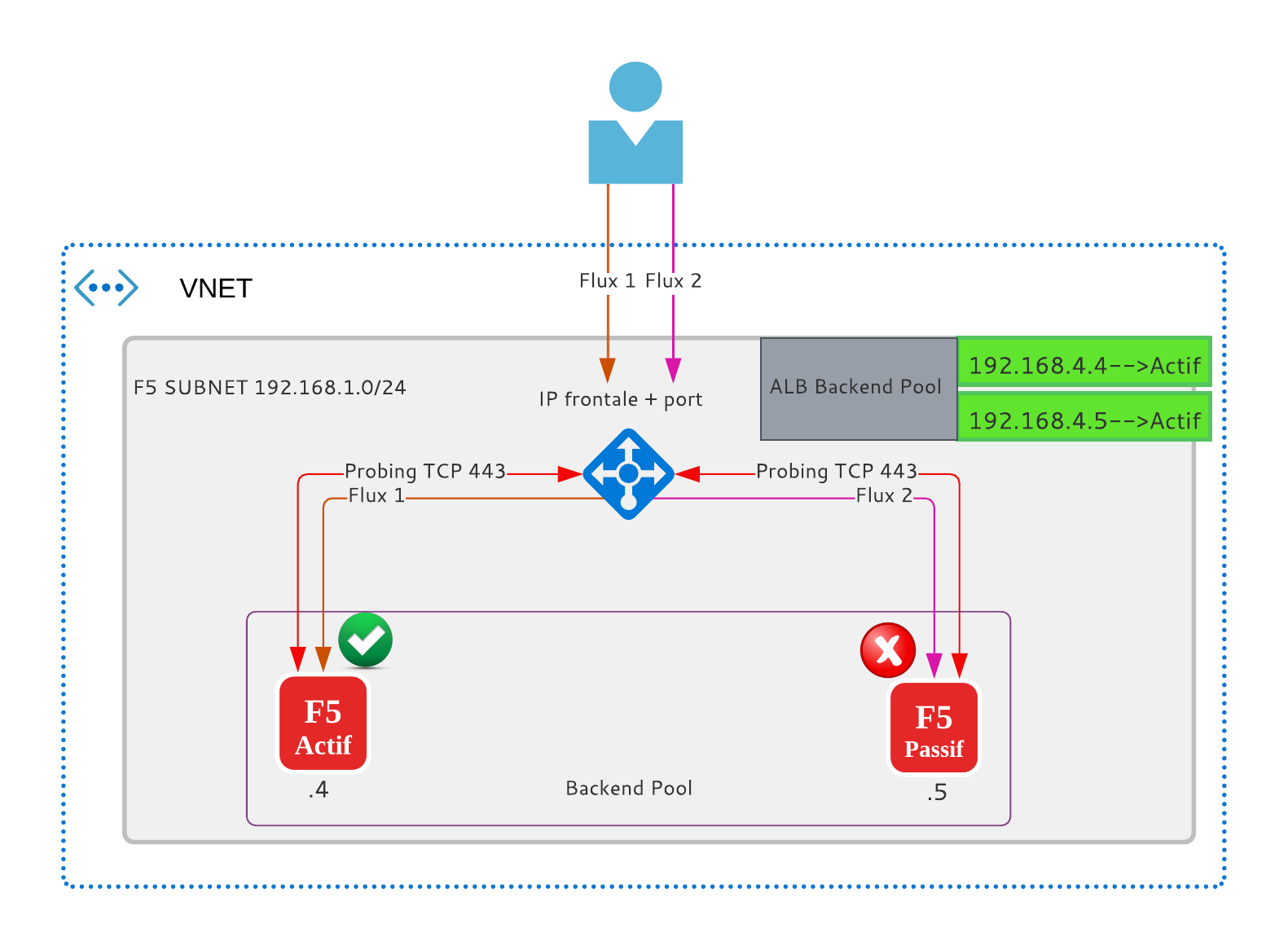
La solution :
Afin que l’ALB puisse détecter que le F5 passif n’est pas un membre actif, il faut logiquement que le F5 cesse à répondre aux Probing envoyés par l’ALB.
Pour cela, on est parti avec la solution suivante :
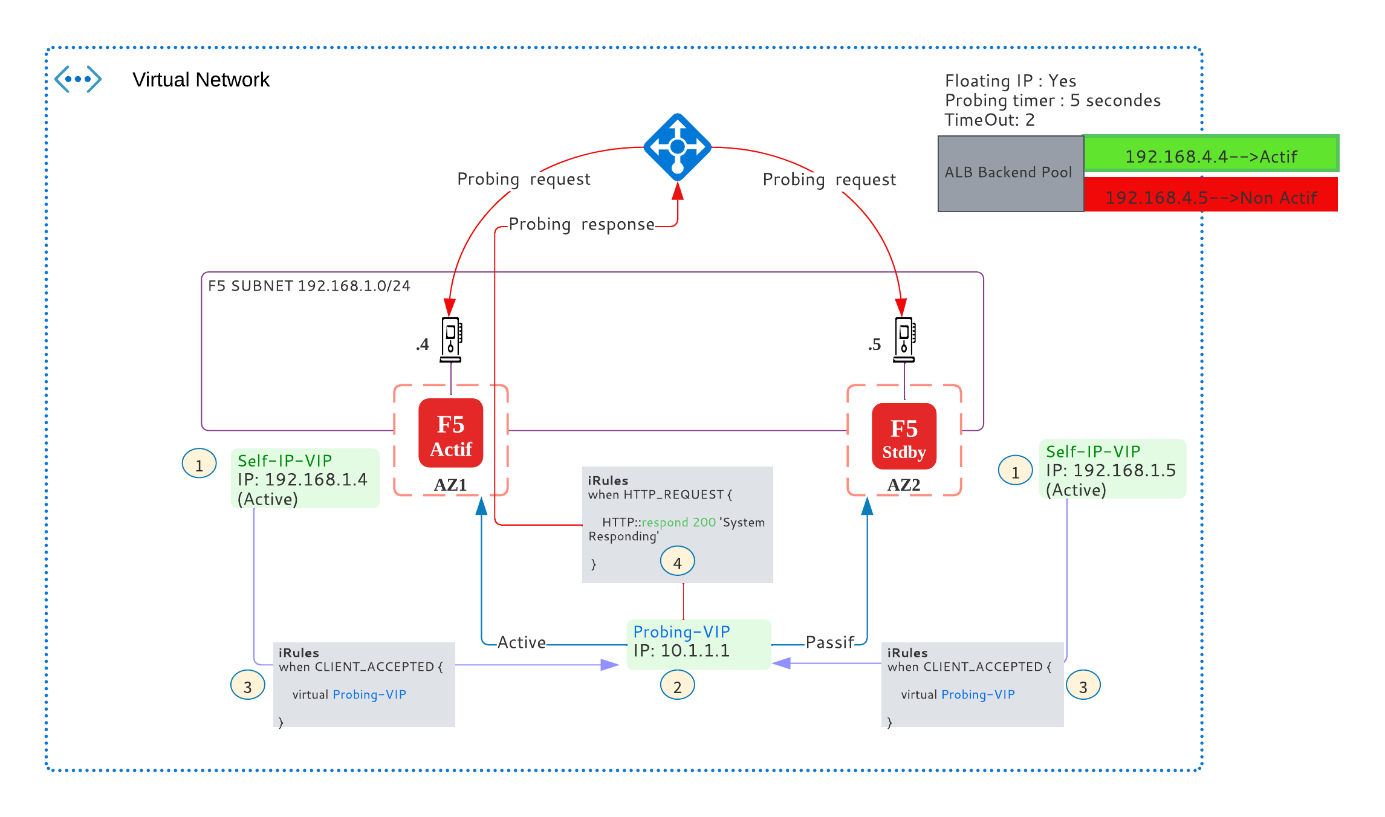
- Dans chaque F5, créer une VIP « Self-IP-VIP » dont l’adresse IP est la Self-IP du F5, la spécificité de cette VIP c’est qu’elle reste locale et elle ne se synchronise pas entre les membres du Cluster. Cette VIP est en écoute sur le port HTTPs.
- Dans le F5 primaire, créer une deuxième VIP « Probing-VIP » qui peux être une adresse IP de votre choix, cette VIP est synchronisée entre le F5 Actif / Passif et effective seulement dans le F5 actif, cette VIP est en écoute sur le port HTTPs.
- Dans chaque F5, créer et associer une règle (iRules) à la « Self-IP-VIP » qui redirige tous le flux HTTPs (ALB Probing) à destination de la VIP vers la « Probing-VIP ».
- Dans le F5 primaire, créer et associer une règle (iRules) à la « Probing VIP » pour répondre directement à l’ALB. En activant l’option automap (Nat Overlad), l’adresse IP source de la réponse devienne la Self-IP du F5.
Le principe de cette configuration est illustré dans le schéma ci-dessous :
En cas de Fail-over, la « Probing-VIP » devient active dans le nouveau F5 primaire, ce dernier répond aux probing de l’ALB et devient le membre actif vis-à-vis de l’ALB :
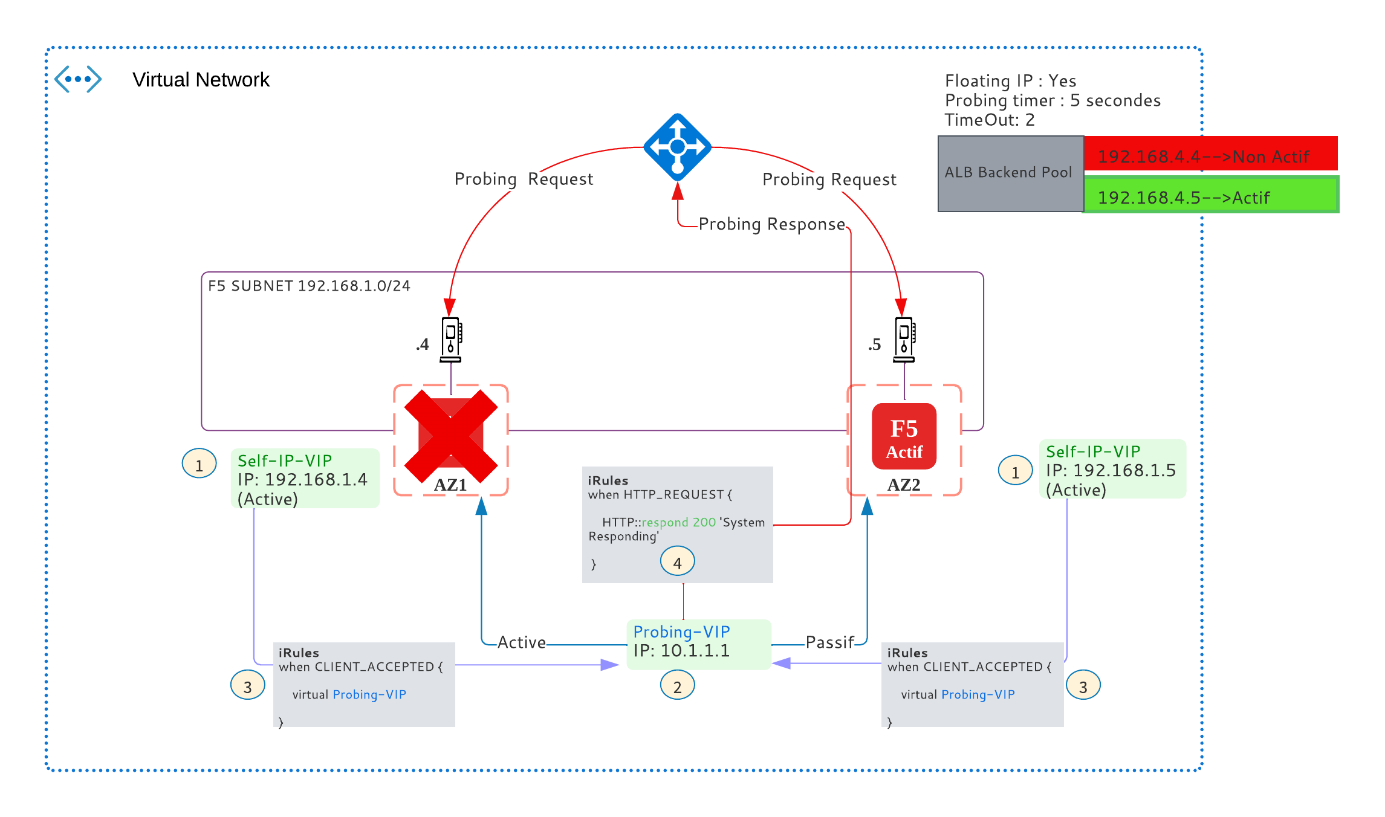
Cette configuration nous a permis de construire un Cluster F5 en mode HA A/P. Avez-vous une meilleure solution pour atteindre le même objectif ? partagez-là avec la communauté en commentaire.