
Les protocoles de routage traditionnels (OSPF, ISIS, EIGRP, BGP, ..) existent depuis plus d’une vingtaine d’année, à cette époque, la préservation des ressources matérielles (CPU, mémoire) sur les équipements actifs était une priorité, par ailleurs, la coupure du réseau pendant plusieurs secondes n’était pas pénalisant pour une grande partie des applications.
Aujourd’hui les besoins ont évolué, les ressources matérielles ne posent plus problème pour une grande partie des équipements actifs et la coupure du réseau doit être minimale : pour certaines applications, la coupure du réseau ne doit pas dépasser la seconde. (sub-second convergence)
Dans cet article, nous allons nous intéresser à l’optimisation des temps de convergence d’un réseau, mais d’abords, commençons par donner une définition simple et facile de ce temps de convergence :
« Le temps de convergence d’un réseau est le temps nécessaire pour que le trafic en cours soit acheminé vers un chemin alternatif ou optimal suite un événement réseau ».
Il peut donc s’agir :
- Soit d’une coupure réseau (lien, équipement actif, autres ..) nécessitant de basculer sur un autre chemin de routage (s’il existe).
- Changement d’une politique de routage (exemple métrique) impliquant un nouveau calcul du chemin le plus optimal.
Comme on peut le constater, ce temps de convergence n’est pas affaire d’un seul routeur/protocole mais plutôt de l’ensemble des routeurs/protocoles impliqués directement ou indirectement dans l’acheminement de ce flux : il doivent tous réagir par rapport à l’événement et se mettre à jour pour permettre au réseau de converger, c’est pour cette raison qu’on parle d’une convergence d’un réseau et non convergence d’un routeur ou d’un protocole réseau.
La mesure du temps de convergence est réalisée à partir de la formule ci-dessous :
Temps (Convergence) = Temps (Détection) + Temps (Transmission) + Temps (Calcul du nouveau chemin) + Temps (Mise à jour table de routage et FIB).
Il faut donc d’abord détecter l’événement indiquant une convergence du réseau, ensuite prévenir et transmettre l’information à l’ensemble de voisins impliqués, calculer ensuite le nouveau chemin optimal et enfin mettre à jour la table de routage et le hardware (FIB).
Dans la suite, nous allons détailler point par point l’ensemble de ces temps et voir quelques options qui permettent de les optimiser et de réduire par conséquent le temps global de convergence du réseau.
Dans les exemples cités ci-dessous, nous allons surtout nous intéresser aux protocoles à état de liens « Link State » (OSPF et ISIS) qui sont le plus déployés en IGP chez les entreprises et opérateurs.
Temps de détection :
Il s’agit du temps nécessaire pour détecter la perte d’un lien réseau avec un voisin avec lequel une relation d’adjacence protocolaire existe, on distingue deux cas :
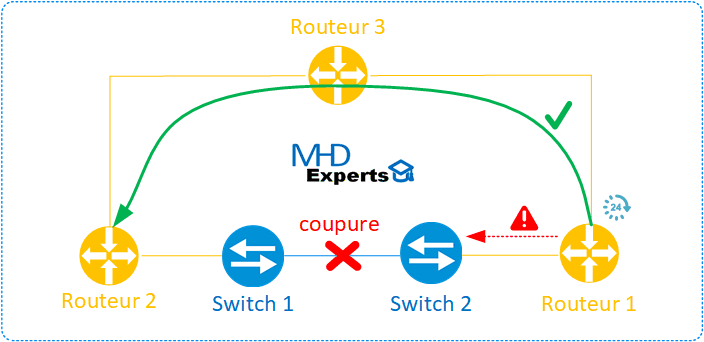
Cas 1 : Voisins directement connectés comme indiqué dans le schéma ci-dessous :

La détection de coupure de lien dans ce cas de figure est très rapide, les mécanismes « Link Debounce/Carrier Delays » implémentés nativement sur les équipements actifs permettent de prévenir rapidement de cette coupure.
Link Debounce : ce paramètre hardware permet d’indiquer le temps qu’une interface réseau attend pour prévenir de la perte du lien, il est généralement configurable sur les switches avec la commande « link debounce time <msec>».
Carrier Delay : ce paramètre software permet d’indiquer le temps à attendre avant de notifier la carte superviseur d’une coupure hardware, il est généralement configurable sur les routeurs avec les commandes « carrier-delay msec <msec> », « carrier-delay up <msec> ».
Cas 2 : Voisins indirectement connectés comme indiqué dans le schéma ci-dessous :
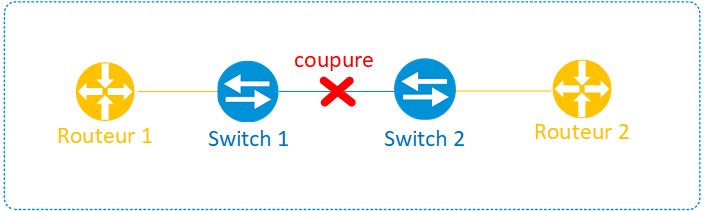
Dans ce cas, la coupure physique du lien inter-switch n’étant pas visible par les routeurs, pour permettre la détection, il existe deux méthodes :
Méthode 1 : implémenter les « Fast Hello » par la réduction des temps « hello/hold timers » sur les protocoles réseaux (HSRP, OSPF, …) afin de détecter rapidement l’indisponibilité d’un voisin.
Méthode 2 : implémenter le protocole BFD (Bidirectional Forwarding Detection) qui a été conçu pour cet effet et qui peut être exécuté sur tout type de média.
En terme de design et d’implémentation, la méthode 1 n’est pas préconisée pour plusieurs raisons : elle peut être très consommatrice en ressources CPU et souvent introduit des « falses positives », elle doit aussi être dupliquée pour tous les protocoles implémentés dans l’architecture (exemple Fast Hello pour OSPF, Fast Hello pour HSRP, …).
La méthode 2 est la bonne pratique en terme de design et d’implémentation pour plusieurs raisons :
- Le protocole BFD est souvent implémenté en hardware sur les cartes de lignes et n’a aucun impact sur les ressources CPU.
- L’ensemble des protocoles (OSPF, EIGRP, HSRP, ..) nécessitant d’avoir une détection rapide souscrivent au protocole BFD et les timers hello/hold de ces protocoles sont laissés à leurs valeurs par défaut.
En terme de configuration (OSPF avec BFD) sur les équipements Cisco :
sur IOS-XE :
IOS-XE(config)# interface
IOS-XE(config-if)# bfd interval 100 min_rx 100 multiplier 4
IOS-XE(config)# router ospf 1
IOS-XE(config-router)# bfd all-interfaces
Sur NX-OS :
NX-OS(config)# interface
NX-OS(config-if)# bfd interval 100 min_rx 100 multiplier 4
NX-OS(config)# router ospf 1
NX-OS(config-router)# bfd
Sur IOS-XR :
RP/0/RSP0/CPU0:XR# configure
RP/0/RSP0/CPU0:XR(config)# router ospf 0
RP/0/RSP0/CPU0:XR(config-ospf)# area 0
RP/0/RSP0/CPU0:XR(config-ospf)# interface
RP/0/RSP0/CPU0:XR(config-ospf-ar-if)# bfd fast-detect
Temps de Transmission :
Il s’agit du temps qu’attend un routeur avant de prévenir ses voisins et transmettre un événement indiquant un changement d’état du réseau, la question qui peut se poser dans ce cas est :
« Pourquoi faut-il attendre pour certains protocoles (exemple OSPF ou ISIS) au risque de pénaliser le réseau par la perte de paquets pendant ce temps ?«
La réponse à cette question est simple : pouvoir envoyer un maximum d’informations en une seule fois afin de diminuer le temps nécessaire pour le calcul du nouveau chemin.
Prenons l’exemple du protocole OSPF : au lieu d’envoyer plusieurs LS Updates consécutives nécessitant chacun une nouvelle exécution de l’algorithme Dijsktra : Shortest Path First (SPF), on envoi un seul LS Update contenant l’ensemble des événements afin d’exécuter le SPF une seule fois et préserver ainsi la CPU des équipements. Cela permet également de rendre le réseau plus stable et ne pas générer à chaque fois un nouveau chemin de routage différent avec le risque de créer des micros boucles de routage « micro-loops ».
Cependant, il ne faut pas aussi trop attendre avant de prévenir ses voisins sinon on risque de ralentir considérablement la convergence du réseau et impacter fortement les applications (exemple flux temps réels).
En OSPF, ce paramètre se configure au niveau du process avec la syntaxe :
timers pacing flood [msec]
Une autre technique utilisée aussi pour contrôler le temps de transmission est « interface event dampening », prenons le cas d’une interface réseau qui bagote continuellement pour des problèmes de liens physiques (exemple toute les secondes UP/DOWN), au lieu d’envoyer à chaque fois une notification de changement de l’état de lien nécessitant de calculer un nouveau chemin de routage sur l’ensemble des équipements concernés, il est préférable de suspendre l’activité de l’interface en appliquant des pénalités et la remettre en service après expiration de ces pénalités, cela permet aussi d’apporter plus de stabilité au réseau, c’est la fonction primaire de la fonctionnalité « interface event dampening »
En terme de configuration, cette fonctionnalité s’implémente au niveau de l’interface réseau avec la syntaxe :
dampening [half-life-period reuse-threshold] [suppress-threshold max-suppress [restart-penalty]]
Temps de calcul du nouveau chemin :
Il s’agit du temps nécessaire pour calculer un nouveau chemin de routage : calculer signifie exécuter un algorithme de routage afin de trouver un « next-hop » valide (exemple DUAL pour EIGRP ou Dijsktra (SPF) pour OSPF/ISIS).
Comme on l’a vu dans la section précédente, pour les protocoles à état de liens (OSPF et ISIS), quand un routeur reçoit un nouveau LSA indiquant une nouvelle mise à jour, il n’exécute pas immédiatement l’algorithme SPF mais il programme (schedule) son exécution à un temps donnée, cela permet de regrouper un maximum de LSA en provenance de plusieurs routeurs du réseau afin d’exécuter une seule fois cet algorithme.
Ce temps de calcul et d’exécution du SPF peut être configuré par plusieurs mécanismes décrits ci-dessous :
SPF throttling :
Les timers throttle permettent de programmer ces temps d’exécution du SPF, ils se configurent avec la syntaxe :
timers throttle spf [spf-start] [spf-hold] [spf-max-wait]
spf-start: Temps d’attente initial pour l’exécution du SPF suite à la réception d’une mise à jour de LSA.
spf-hold: Temps d’attente minimal entre deux exécutions consécutifs du SPF, ce temps est doublé à chaque execution.
spf-max-wait : Temps d’attente maximal entre deux exécutions consécutifs du SPF, ce temps permet de définir aussi combien de temps le réseau doit rester stable (absence de LS Updates) avant de réinitialiser les timers (spf-start et spf-hold).
Exemple :
timers throttle spf 50 100 5000
Dans cet exemple, quand un LSA est reçu, il est programmé pour être exécuté après 50 msec, si un autre LSA est reçu avant ces 50 msec, il est temporisé aussi avec le LSA précédent, après l’expiration des 50 msec, le protocole SPF sera exécuté (SPF Run).
Le routeur attend 100 ms (hold time), si pendant ce temps un autre LSA est reçu, il sera traité après expiration des 100 ms (SPF Run) et le hold time passe cette fois ci au double (200 ms).
Cette valeur (hold time) est doublé à nouveau jusqu’à non réception de LSA Update.
5000 ms (5 sec) est la valeur maximale entre deux SPF runs, il s’agit aussi de la valeur maximale du hold time.
LSA Throttling :
Cette fonctionnalité permet de définir le temps à attendre pour la génération des LSA pendant une instabilité du réseau, avant cette fonctionnalité, la génération des LSA était fixée par défaut à 5 secondes (LSA-wait timer interval), ce qui rendait impossible une convergence de l’OSPF en moins d’une seconde.
Le principe de fonctionnement de cette fonctionnalité est similaire au “SPF Throttling », la syntaxe pour configurer cette fonctionnalité est :
timers throttle lsa [lsa-start] [lsa-hold] [lsa-max]
lsa-start: Temps d’attente initial pour émettre un LSA, la valeur 0 indique qu’il faut le générer immédiatement.
lsa-hold: Temps d’attente minimum entre émission de deux LSA consécutifs, par défaut, la valeur de ce champs est de 5 secondes et double à chaque fois qu’il faut générer le même LSA.
lsa-max : Temps d’attente maximal entre émission de deux LSA consécutifs, par défaut, la valeur de ce champs est de 5 secondes, il permet aussi d’indiquer la valeur maximale du champs lsa-hold.
Exemple :
timers throttle lsa 0 20 1000
Dans cet exemple, le premier LSA est émis immédiatement (valeur 0), ensuite le hold time est de 20 msec, si pendant ce temps, d’autres LSA doivent être émis, il faut attendre l’expiration des 20 msec.
Le hold-time est ensuite doublé et passe à 40 msec, si pendant ce temps les LSA doivent être émis, il faut attendre expiration de ce timer et sa valeur sera de nouveau doublé. etc etc
Le maximum que le routeur attendra pour émettre les LSA est de 1000 ms (1sec).
LSA ARRIVAL :
Ce temps permet d’indiquer le temps d’attente avant d’accepter un même LSA. Si ce dernier arrive avant ce temps, il sera rejeté par le routeur.
Il est par ailleurs préconisé de configurer la valeur de ce champs inférieure ou égale à la valeur de « hold-interval » des throttle lsa indiqué de la section précédente.
La syntaxe pour configurer ce paramètre est :
timers lsa arrival [msec]
Incremental SPF (iSPF) :
Les protocoles réseaux à état de liens (OSPF et ISIS) exécutent l’algorithme Dijkstra SPT afin de calculer le chemin le plus court vers l’ensemble des nœuds du réseau : quand un changement intervient sur le réseau (exemple déclaration d’un nouveau sous-réseau), l’entière topologie est recalculée sur l’ensemble des routeurs concernés.
Ce calcul global de l’entière topologie (mode par défaut) est souvent inutile puisqu’une grande partie du réseau n’a pas été modifiée (exemple modification faite sur les extrémités du réseau ou sur un lien non utilisé par le chemin le plus court).
La fonctionnalité Incremental SPF (iSPF) permet d’optimiser la méthode de calcul par défaut et d’exécuter le SPT uniquement sur la partie concernée par la modification, cela permet d’optimiser l’utilisation des ressources CPU sur les équipements, calculer plus vite le chemin le plus court et par conséquent converger le réseau plus rapidement.
A noter que sur certaines gammes de routeurs haut de gamme, la fonctionnalité iSPF n’est plus implémentée : les performances des équipements CPU sont tellement importantes que le gain de la fonctionnalité iSPF est très minime, par conséquent, il est préférable d’exécuter le SPF entier sur la topologie.
La syntaxe pour configurer ce paramètre est :
router ospf 1
ispf
Implémentation par défaut sur les équipements Cisco :
Sur IOS, Observons les valeurs par défaut des paramètres décrits plus haut :
IOS#sh ip ospf
Initial SPF schedule delay 5000 msecs
Minimum hold time between two consecutive SPFs 10000 msecs
Maximum wait time between two consecutive SPFs 10000 msecs
Minimum LSA interval 5 secs
Minimum LSA arrival 1000 msecs
Ce qui donne la configuration par défaut ci-dessous :
router ospf 1
timers throttle spf 5000 10000 10000
timers throttle lsa 0 5000 5000
SPF throttling :
spf-start : 5000 msec (5 secondes)
spf-hold : 10000 msec (10 secondes)
spf-max-wait : 10000 msec (10 secondes)
LSA Throttling :
lsa-start : 0 msec
lsa-hold : 5000 msec (5 secondes)
lsa-max : 5000 msec (5 secondes)
=> Les paramètres par défaut sur IOS ne permettent une convergence inférieure à la seconde, en effet, le SPF n’est exécuté que 5 secondes après la réception du premier LSA indiquant une mise à jour.
A noter que sur les dernières versions d’IOS-XE (exemple en version 16.09.02), ces valeurs sont maintenant pré-configurés automatiquement pour tenir compte par défaut les mécanismes de convergence rapide.
Le message de logs ci-dessous est affiché pour indiquer la prise en compte des mécanismes de « Fast convergence » :
%OSPF-6-DFT_OPT: Protocol timers for fast convergence are Enabled.
IOS-XE#sh ip ospf
Initial SPF schedule delay 50 msecs
Minimum hold time between two consecutive SPFs 200 msecs
Maximum wait time between two consecutive SPFs 5000 msecs
Initial LSA throttle delay 50 msecs
Minimum hold time for LSA throttle 200 msecs
Maximum wait time for LSA throttle 5000 msecs
Minimum LSA arrival 100 msecs
Dans cette configuration générée automatiquement par le routeur, les valeurs utilisées sont :
SPF throttling :
spf-start : 50 msec
spf-hold : 200 msec
spf-max-wait : 5000 msec (5secondes)
LSA Throttling :
lsa-start : 50 msec
lsa-hold : 200 msec
lsa-max : 5000 msec (5 secondes)
Temps de mise à jour table de routage et FIB :
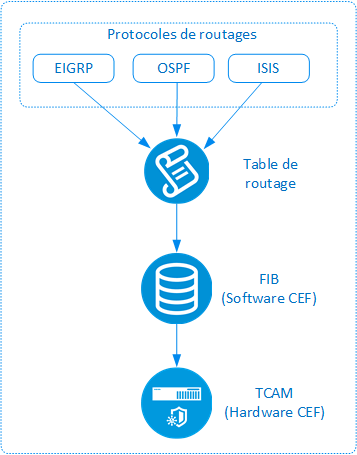
Il s’agit du temps nécessaire aux protocoles de routages (OSPF, EIGRP, ..) pour mettre à jour la table de routage de l’équipement et ensuite programmer la FIB (Forwarding Information Base) pour tenir compte de la nouvelle topologie du réseau.
Cette étape est très dépendante du nombre de routes à programmer ainsi que du matériel utilisé, cependant, les temps d’exécution de cette étape restent relativement faible sur la génération de routeurs actuels (ASR, NEXUS, ..).
Le schéma ci-dessous résume l’ensemble de ces étapes :
Quelques optimisations restent cependant possibles durant cette étape :
OSPF prefix-suppresion : Cette fonctionnalité permet de réduire considérablement le nombre de LSA à installer dans la table de routage par la suppression des LSA type 1 (routeur) et type 2 (network) correspondant aux sous-réseaux d’interconnexions (transit link) entre les équipements actifs.
Exemple : Dans une architecture MPLS VPN, au sein d’un AS, les routeurs communiquent entre eux à travers leur interface loopback pour établir les sessions iBGP et construire les LSP (Label Switched Path), ils n’ont pas besoin d’avoir connaissance des sous-réseau d’interconnexions des autres routeurs.
ISIS advetise passive-only : Cette fonctionnalité a la même finalité que l’option prefix-suppresion de l’OSPF. Elle s’applique pour le protocole ISIS et permet de restreindre les réseaux à annoncer en ISIS (exemple uniquement les interfaces loopback).
OSPF/IS-IS LFA (Loop Free Alternate), BGP PIC (Prefix Independant Convergence) : Ces fonctionnalités permettent d’être proactif et de pré-calculer un chemin de secours (repair path) pour le programmer au préalable dans la FIB, en cas de coupure, ce chemin sera activé immédiatement et permettra dans les environnements disposant de plusieurs milliers de routes (exemple BGP sur Internet) de réduire considérablement les temps de convergence. (inférieur à la seconde).
Conclusion :
Cet article permet de donner un bon aperçu sur quelques options permettant d’améliorer considérablement les temps de convergence du réseau et plus particulièrement pour les protocoles OSPF et ISIS, ces options permettent aussi d’apporter plus de stabilité au fonctionnement du réseau.
Il ne faut pas oublier qu’en terme de design réseau, il est souvent question de compromis (trade-offs), on peut améliorer une partie du réseau et en impacter une autre, c’est pour cette raison qu’il faut rester très vigilant dans le paramétrage de ces options et ne pas être trop agressif pour au final obtenir le même résultat : le réseau doit être conçu pour les applications et non le contraire.
Le choix des mécanismes de convergence décrit dans cet article va aussi dépendre fortement de l’environnement sur lesquelles elles seront implémentées, en effet, les contraintes imposées par certaines applications (exemple finance, temps réel, ..) permettent de définir les bonnes pratiques à appliquer.
Enfin, Il existe d’autres fonctionnalités avancées qui permettent d’améliorer considérablement les temps de convergence au niveau du plan de donnée (data plane) et qui ne sont pas traités dans cet article (exemple OSPF Loop Free Alternate (LFA), BGP Prefix Independent Convergence (PIC), ..), un article entier leur sera dédié prochainement.
J’espère qu’avec cet article, vous savez mieux maintenant comment améliorer les temps de convergence de votre réseau et comment aussi le rendre plus stable.
Si vous avez des questions, n’hésitez pas à laisser un message en commentaire de la page ou nous contacter à l’adresse : contact@mhd-experts.com.